

اعتبارسنجی فرضیهها در کشف علمی، تصمیمگیری و کسب اطلاعات اساسی است. چه در زیستشناسی، اقتصاد یا سیاستگذاری، محققان برای هدایت نتایج خود به آزمایش فرضیهها تکیه میکنند. بهطور سنتی، این فرآیند شامل طراحی آزمایشها، جمعآوری دادهها و تجزیه و تحلیل نتایج برای تعیین اعتبار یک فرضیه است. با این حال، حجم فرضیههای تولید شده با ظهور LLM ها به طور چشمگیری افزایش یافته است. در حالی که این فرضیههای مبتنی بر هوش مصنوعی بینشهای جدیدی را ارائه میدهند، اما میزان باورپذیری آنها بسیار متفاوت است و اعتبارسنجی دستی را غیرعملی میکند. بنابراین، اتوماسیون در اعتبارسنجی فرضیهها به یک چالش اساسی در تضمین این موضوع تبدیل شده است که فقط فرضیههای علمی دقیق، تحقیقات آینده را هدایت کنند.
چالش اصلی در اعتبارسنجی فرضیهها این است که بسیاری از فرضیههای دنیای واقعی انتزاعی هستند و مستقیماً قابل اندازهگیری نیستند. به عنوان مثال، بیان اینکه یک ژن خاص باعث ایجاد یک بیماری میشود، بسیار کلی است و باید به پیامدهای قابل آزمایش ترجمه شود. ظهور LLM ها این موضوع را تشدید کرده است، زیرا این مدلها فرضیهها را در مقیاسی بیسابقه تولید میکنند که بسیاری از آنها ممکن است نادرست یا گمراهکننده باشند. روشهای اعتبارسنجی موجود برای همگام شدن با این سرعت با مشکل مواجه هستند و تعیین اینکه کدام فرضیهها ارزش بررسی بیشتر را دارند، دشوار است. همچنین، دقت آماری اغلب به خطر میافتد و منجر به تأییدیههای نادرست میشود که میتواند تلاشهای تحقیقاتی و سیاستگذاری را به بیراهه بکشاند.
[وبینار رایگان پیشنهادی] چگونه به دسترسی بدون اعتماد به Kubernetes به راحتی دست یابیم (تبلیغ شده)
روشهای سنتی اعتبارسنجی فرضیهها شامل چارچوبهای آزمایش آماری مانند آزمایش فرضیه مبتنی بر مقدار p و آزمون ترکیبی فیشر است. با این حال، این رویکردها برای طراحی آزمایشهای ابطال و تفسیر نتایج به مداخله انسانی متکی هستند. رویکردهای خودکار دیگری نیز وجود دارند، اما اغلب فاقد سازوکارهایی برای کنترل خطاهای نوع اول (مثبت کاذب) و اطمینان از اینکه نتایج از نظر آماری قابل اعتماد هستند، میباشند. بسیاری از ابزارهای اعتبارسنجی مبتنی بر هوش مصنوعی به طور سیستماتیک فرضیهها را از طریق ابطال دقیق به چالش نمیکشند و خطر یافتههای گمراهکننده را افزایش میدهند. در نتیجه، یک راهحل مقیاسپذیر و از نظر آماری sound مورد نیاز است تا فرآیند اعتبارسنجی فرضیهها را به طور موثر خودکار کند.
محققان دانشگاه استنفورد و دانشگاه هاروارد POPPER را معرفی کردند، یک چارچوب عاملمحور که با ادغام اصول آماری دقیق با عوامل مبتنی بر LLM، فرآیند اعتبارسنجی فرضیهها را خودکار میکند. این چارچوب به طور سیستماتیک اصل ابطال کارل پاپر را اعمال میکند، که بر رد کردن فرضیهها به جای اثبات آنها تأکید دارد. POPPER از دو عامل تخصصی مبتنی بر هوش مصنوعی استفاده میکند:
- عامل طراحی آزمایش که آزمایشهای ابطال را فرموله میکند
- عامل اجرای آزمایش که آنها را پیادهسازی میکند
هر فرضیه به زیرفرضیههای خاص و قابل آزمایش تقسیم میشود و تحت آزمایشهای ابطال قرار میگیرد. POPPER با پالایش مداوم فرآیند اعتبارسنجی و جمعآوری شواهد، تضمین میکند که فقط فرضیههایی که به خوبی پشتیبانی میشوند، پیشرفت میکنند. برخلاف روشهای سنتی، POPPER به طور پویا رویکرد خود را بر اساس نتایج قبلی تطبیق میدهد و به طور قابل توجهی کارایی را بهبود میبخشد در حالی که یکپارچگی آماری را حفظ میکند.
POPPER از طریق یک فرآیند تکراری عمل میکند که در آن آزمایشهای ابطال به طور متوالی فرضیهها را آزمایش میکنند. عامل طراحی آزمایش این آزمایشها را با شناسایی پیامدهای قابل اندازهگیری یک فرضیه معین تولید میکند. سپس عامل اجرای آزمایش، آزمایشهای پیشنهادی را با استفاده از روشهای آماری، شبیهسازیها و جمعآوری دادههای دنیای واقعی انجام میدهد. نکته کلیدی در روششناسی POPPER، توانایی آن در کنترل دقیق نرخهای خطای نوع اول است و تضمین میکند که مثبتهای کاذب به حداقل میرسند. برخلاف رویکردهای مرسوم که مقادیر p را به صورت جداگانه در نظر میگیرند، POPPER یک چارچوب آزمایش متوالی را معرفی میکند که در آن مقادیر p فردی به مقادیر e تبدیل میشوند، یک معیار آماری که امکان جمعآوری شواهد مداوم را در حین حفظ کنترل خطا فراهم میکند. این رویکرد تطبیقی سیستم را قادر میسازد تا فرضیههای خود را به صورت پویا پالایش کند و شانس رسیدن به نتایج نادرست را کاهش دهد. انعطافپذیری چارچوب به آن اجازه میدهد تا با مجموعههای داده موجود کار کند، شبیهسازیهای جدیدی انجام دهد یا با منابع داده زنده تعامل داشته باشد و آن را در بین رشتهها بسیار متنوع میکند.
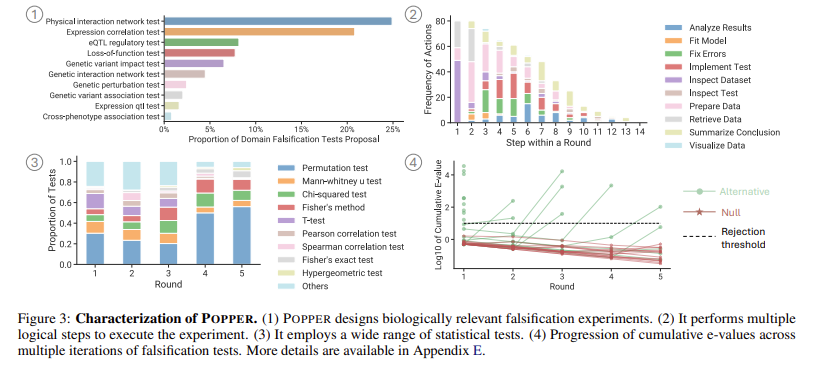
چند نکته کلیدی از این تحقیق عبارتند از:
- POPPER یک راهحل مقیاسپذیر و مبتنی بر هوش مصنوعی ارائه میکند که ابطال فرضیهها را خودکار میکند، حجم کار دستی را کاهش میدهد و کارایی را بهبود میبخشد.
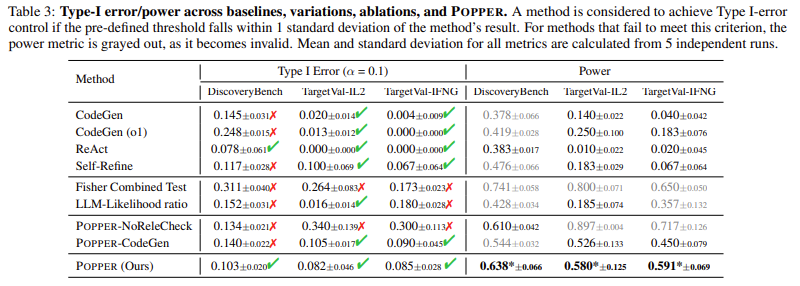
- این چارچوب کنترل دقیق خطای نوع اول را حفظ میکند و تضمین میکند که مثبتهای کاذب زیر 0.10 باقی میمانند، که برای یکپارچگی علمی بسیار مهم است.
- در مقایسه با محققان انسانی، POPPER اعتبارسنجی فرضیهها را 10 برابر سریعتر تکمیل میکند و به طور قابل توجهی سرعت کشف علمی را بهبود میبخشد.
- برخلاف آزمایش مقدار p سنتی، استفاده از مقادیر e امکان جمعآوری شواهد تجربی را در حین پالایش پویای اعتبارسنجی فرضیهها فراهم میکند.
- در شش زمینه علمی از جمله زیستشناسی، جامعهشناسی و اقتصاد آزمایش شده است که نشاندهنده کاربرد گسترده است.
- دقت POPPER که توسط نه دانشمند در سطح دکترا ارزیابی شده است، با عملکرد انسانی مطابقت داشت در حالی که زمان صرف شده برای اعتبارسنجی را به طور چشمگیری کاهش داد.
- قدرت آماری را 3.17 برابر بیشتر از روشهای اعتبارسنجی فرضیه سنتی بهبود بخشید و از نتایج قابل اعتمادتر اطمینان حاصل کرد.
- POPPER مدلهای زبان بزرگ را برای تولید و پالایش پویای آزمایشهای ابطال ادغام میکند و آن را با نیازهای تحقیقاتی در حال تحول سازگار میکند.
مقاله و صفحه GitHub را بررسی کنید. تمام اعتبار این تحقیق به محققان این پروژه میرسد. همچنین، در توییتر ما را دنبال کنید و فراموش نکنید که به SubReddit 75k+ ML ما بپیوندید.
 خواندن پیشنهادی- LG AI Research NEXUS را منتشر میکند: یک سیستم پیشرفته
یکپارچهسازی سیستم هوش مصنوعی عامل و استانداردهای انطباق با دادهها برای رسیدگی به نگرانیهای قانونی در مجموعههای داده هوش مصنوعی
خواندن پیشنهادی- LG AI Research NEXUS را منتشر میکند: یک سیستم پیشرفته
یکپارچهسازی سیستم هوش مصنوعی عامل و استانداردهای انطباق با دادهها برای رسیدگی به نگرانیهای قانونی در مجموعههای داده هوش مصنوعی