
NVIDIA ACE مجموعهای از فناوریهای دیجیتال انسانی است که شخصیتهای بازی و دستیارهای دیجیتال را با استفاده از هوش مصنوعی مولد زنده میکند. مدلهای ACE روی دستگاه، گردشهای کاری عامل را برای شخصیتهای بازی مستقل فعال میکنند که میتوانند محیط خود را درک کنند، ورودیهای چندوجهی را بفهمند، مجموعهای از اقدامات را بهطور استراتژیک برنامهریزی کرده و همه آنها را در زمان واقعی اجرا کنند، و تجربههای پویایی را برای بازیکنان فراهم آورند.
برای اجرای این مدلها در کنار موتور بازی، SDK استنتاج درون بازی NVIDIA (NVIGI) به شما امکان میدهد استنتاج هوش مصنوعی را مستقیماً در بازیها و برنامههای C++ برای عملکرد و تأخیر بهینه ادغام کنید.
این پست نشان میدهد که چگونه NVIGI با ACE ادغام میشود تا استنتاج یکپارچه هوش مصنوعی را در توسعه بازی فعال کند. ما معماری NVIGI، ویژگیهای کلیدی و نحوه شروع ایجاد شخصیتهای مستقل با مدلهای ACE روی دستگاه NVIDIA را پوشش میدهیم.
مدلهای NVIDIA ACE روی دستگاه
NVIDIA ACE گفتار، هوش و انیمیشن را با استفاده از هوش مصنوعی مولد فعال میکند. این مجموعه، مجموعهای از مدلهای هوش مصنوعی را ارائه میدهد که شخصیتهای بازی را قادر میسازد تا بر اساس تعاملات بازیکن در زمان واقعی، درک کنند، استدلال کنند و عمل کنند:
- درک: مدل آتی NeMoAudio-4B-Instruct تعاملات شخصیت را با آگاهی زمینهای بیشتر از صدا افزایش میدهد. شما میتوانید به راحتی مدلهای چندوجهی بیشتری را ادغام کنید تا با گنجاندن ورودیهای حسی اضافی، این قابلیتها را بیشتر گسترش دهید.
- شناخت: خانواده Mistral-Nemo-Minitron-Instruct از مدلهای زبانی کوچک، از نظر قابلیتهای پیروی از دستورالعملها، در صدر جدول قرار دارند و شخصیتها را قادر میسازند تا بهطور دقیق ایفای نقش کنند.
- حافظه: مدلهای جاسازی مانند E5-Large-Unsupervised شخصیتها را قادر میسازند تا تعاملات گذشته را به یاد بیاورند و غوطهوری را غنیتر کنند.
- انیمیشن: انیمیشن مبتنی بر هوش مصنوعی بیدرنگ مانند Audio2Face همگامسازی دقیق لب را برای احساسات پویا و سرزنده ارائه میدهد.
- عمل: رابطهای ساده و منطق سفارشی شخصیتها را قادر میسازند تا اقدامات معناداری انجام دهند، از انتخاب پاسخهای درون بازی گرفته تا اجرای برنامههای استراتژیک از طریق تصمیمگیری و درخواستهای مبتنی بر مدل.
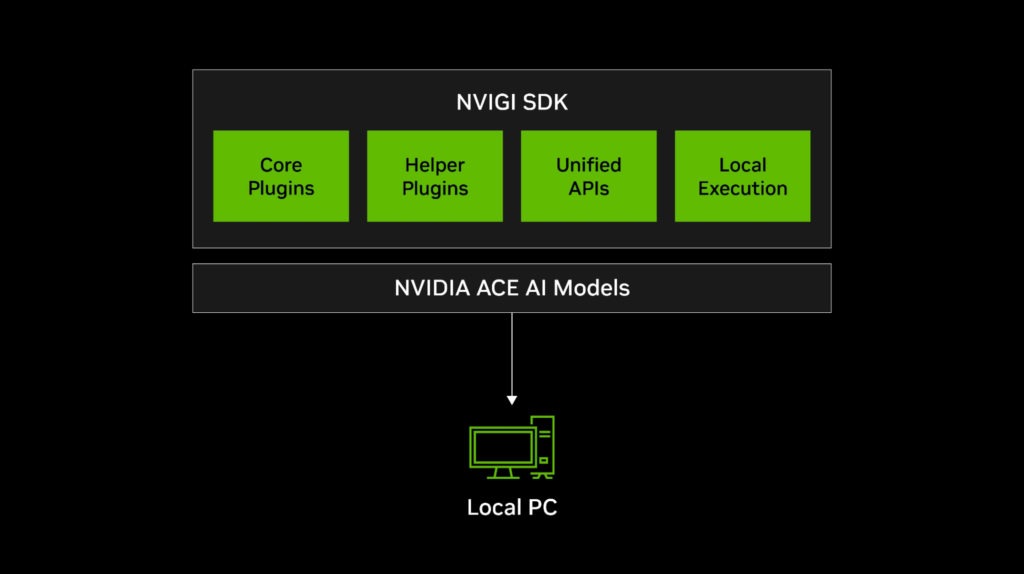
SDK استنتاج درون بازی NVIDIA چیست؟
SDK NVIGI یک مدیر استنتاج مبتنی بر پلاگین و بهینهسازیشده GPU است که برای سادهسازی ادغام مدلهای ACE در بازی و برنامههای تعاملی طراحی شده است. این قابلیتها را ارائه میدهد:
- انعطافپذیری پلاگین: پلاگینهای هوش مصنوعی (ASR، مدلهای زبانی، جاسازیها) را به راحتی اضافه، بهروزرسانی و مدیریت کنید.
- DLLهای بومی ویندوز: گردشهای کاری را برای بازیها و برنامههای C++ ساده کنید.
- بهینهسازی GPU: از فناوری محاسبه در گرافیک (CIG) برای استنتاج کارآمد هوش مصنوعی در کنار وظایف رندرینگ استفاده کنید.
با ترکیب NVIGI با ACE، میتوانید شخصیتهای مستقلی با قابلیتهای پیشرفته هوش مصنوعی مولد ایجاد کنید، مانند گفتگوی NPC بیدرنگ، حافظه زمینهای و انیمیشن زنده.
NVIGI چگونه کار میکند
در هسته خود، معماری NVIGI مبتنی بر پلاگینهای مدولار است که ادغام انعطافپذیر عملکردهای مختلف هوش مصنوعی را فعال میکنند:
- پلاگینهای اصلی: قابلیتهای هوش مصنوعی مانند تشخیص گفتار خودکار (ASR)، استدلال مولد و بازیابی جاسازی را ارائه میدهند.
- پلاگینهای کمکی: ابزارهایی مانند زمانبندی GPU و ارتباطات شبکه را مدیریت میکنند.
- APIهای یکپارچه: مدیریت پلاگین را ساده کرده و پیچیدگی کد را کاهش میدهند.
- اجرای محلی و ابری: از استنتاج روی دستگاه (CPU/GPU) و گردشهای کاری هوش مصنوعی مبتنی بر ابر پشتیبانی میکند.
این اجزا با هم کار میکنند تا یک تجربه بازی مبتنی بر هوش مصنوعی یکپارچه ارائه دهند. برای مثال، تصور کنید بازیکنی سؤالی از یک NPC میپرسد. NVIGI یک گردش کار عامل را هماهنگ میکند و شخصیتها را قادر میسازد تا در زمان واقعی گوش دهند، استدلال کنند، صحبت کنند و انیمیشن دهند.
این فرآیند چند مرحله کلیدی را دنبال میکند:
- با ASR به کاربران گوش دهید: NPC گفتار بازیکن را با استفاده از NVIDIA Riva ASR پردازش میکند و ورودی گفتاری را به متن برای استدلال بیشتر تبدیل میکند.
- با یک SLM پاسخی ایجاد کنید: متن رونویسیشده به یک مدل زبانی کوچک (SLM) مانند Mistral-Nemo-Minitron-128K-Instruct منتقل میشود که پاسخی پویا و مرتبط با زمینه ایجاد میکند. اگر زمینه اضافی مورد نیاز باشد، میتوان از یک رویکرد تولید تقویتشده بازیابی (RAG) استفاده کرد، جایی که یک مدل جاسازی مانند E5-Large-Unsupervised متن را به بازنماییهای برداری تبدیل میکند. سپس از این بردارها در جستجوی شباهت برای بازیابی دانش مرتبط استفاده میشود و پاسخ SLM را با زمینه اضافی غنی میکند.
- به شخصیتها صدایی با TTS بدهید: پاسخ تولیدشده به صداهای زنده تبدیل میشود و لحن و بیان طبیعی را تضمین میکند.
- انیمیشن تعاملی ایجاد کنید: سپس پاسخ گفتاری، ترکیبهای چهره را برای انیمیشن بیدرنگ با استفاده از Audio2Face-3D هدایت میکند و همگامسازی دقیق لب و حرکات بیانی شخصیت را تضمین میکند.
در طول این فرآیند، زمانبندی GPU و CiG تضمین میکنند که بارهای کاری استنتاج هوش مصنوعی در کنار وظایف رندرینگ اجرا میشوند و در عین حال تأثیر بر نرخ فریم را به حداقل میرسانند. این یک تجربه بیدرنگ و یکپارچه را تضمین میکند.
برای اطلاعات بیشتر در مورد پیادهسازی این پلاگینها و مدلها برای اجرای درون فرآیندی، به بخشهای بعدی مراجعه کنید.
شروع به کار با استنتاج ACE روی دستگاه
این بخش نحوه استفاده از NVIGI با ACE SLMها را برای فعال کردن استنتاج هوش مصنوعی درون فرآیندی در کنار بارهای کاری رندرینگ شما شرح میدهد.
NVIGI شامل فایلهای دستهای است که مدلها را از مخازنی مانند NVIDIA NGC و Huggingface دریافت میکنند. این کار دانلود اولیه را به حداقل میرساند و تضمین میکند که فقط مدلهایی را دانلود میکنید که میخواهید با آنها کار کنید. همچنین شامل مجموعهای از پلاگینهای استنتاج محلی است که بعداً برای کمک به شما در شروع کار، آنها را برجسته میکنیم.
مقداردهی اولیه NVIGI
اولین قدم، مقداردهی اولیه چارچوب NVIGI است. این فرآیند مسیرهای پلاگین، ورود به سیستم و پیکربندیهای اصلی مورد نیاز NVIGI برای عملکرد در بازی شما را تنظیم میکند.
مثال کد زیر نحوه مقداردهی اولیه NVIGI در بازی شما را نشان میدهد:
nvigi::Preferences preferences{};
preferences.logLevel = nvigi::LogLevel::eVerbose; // فعال کردن ورود به سیستم پرمخاطب
preferences.utf8PathsToPlugins = {"path/to/plugins"}; // تنظیم مسیر پلاگین
preferences.utf8PathToLogsAndData = "path/to/logs"; // تعریف مسیر ورود به سیستم
if (nvigiInit(preferences, nullptr, nvigi::kSDKVersion) != nvigi::kResultOk) {
std::cerr << "Failed to initialize NVIGI." << std::endl;
}بارگیری پلاگینها و مدل
معماری NVIGI حول یک سیستم پلاگین ساخته شده است که مدولاریته و انعطافپذیری را ارائه میدهد. پلاگینها برای کلاسهای مدل هوش مصنوعی مانند LLMها، ASR و بازیابی جاسازی گنجانده شدهاند. این پلاگینها شما را قادر میسازند تا مدلهای هوش مصنوعی را از محدوده ACE مستقر کنید تا ویژگیها و رفتارهایی را که نیاز دارید پیادهسازی کنید.
هر پلاگین به گونهای طراحی شده است که از چندین مدل پشتیبانی کند که یک باطن تعیینشده و API زیربنایی را به اشتراک میگذارند. NVIGI شامل پلاگینهای درون فرآیندی با پشتیبانی از باطنهای محبوب مانند GGML (llama.cpp, whisper.cpp, embedding.cpp)، ONNX Runtime و DirectML است.
در اینجا چند نمونه آورده شده است:
nvigi.plugin.asr.ggml.cuda: با استفاده از GGML و CUDA گفتار را به متن تبدیل میکند.nvigi.plugin.gpt.ggml.cuda: گفتگوی تولیدشده با هوش مصنوعی و استدلال را تقویت میکند.nvigi.plugin.embed.ggml.*: متن مربوطه را بر اساس احساسات پیدا میکند تا زمینه بهتری ارائه دهد.
برای استفاده از پلاگین GPT، ابتدا رابط آن را بارگیری کنید تا قابلیتهای مدل را پرس و جو کنید:
// بارگیری رابط پلاگین GPT
nvigi::IGeneralPurposeTransformer* gpt = nullptr;
nvigiGetInterfaceDynamic(nvigi::plugin::gpt::ggml::cuda::kId, &gpt, ptr_nvigiLoadInterface);NVIGI از قبل با مجموعهای از مدلهای قابل دانلود دستی برای شروع کار بارگیری شده است، اما میتوانید مدلهای GGUF بیشتری را از NGC یا Huggingface دریافت کنید. سپس پارامترهای مدل را برای پلاگین تعریف میکنید، مانند مثال زیر:
// پیکربندی پارامترهای مدل
nvigi::CommonCreationParameters common{};
common.utf8PathToModels = "path/to/models";
common.numThreads = 8; // تعداد رشتههای CPU
common.vramBudgetMB = vram; // تخصیص VRAM در MB
common.modelGUID = "{YOUR_MODEL_GUID}"; // Model GUIDهنگامی که رابط و پارامترهای مدل بارگیری شدند، یک نمونه یا استنتاج درون فرآیندی را پیکربندی کنید:
// ایجاد نمونه GPT
nvigi::InferenceInstance* gptInstance = nullptr;
if (gpt->createInstance(common, &gptInstance) != nvigi::kResultOk || !gptInstance) {
std::cerr << "Failed to create GPT instance." << std::endl;
}
// استفاده از نمونه GPT برای استنتاجایجاد پیکربندی زمان اجرا و استنتاج
رابط InferenceInstance API را برای اجرای وظایف استنتاج فراهم میکند و از طریق InferenceExecutionContext پیکربندی میشود. این رابط، تنظیم اسلاتهای ورودی، پارامترهای زمان اجرا و مکانیسمهای بازخوانی برای بازیابی پاسخهای مدل را فعال میکند.
وظایف استنتاج به دادههای ورودی مانند متن یا صدای بازیکن، همراه با پیکربندیهای زمان اجرا متکی هستند. زمینه برای تعریف شخصیت و نقش یک شخصیت بازی را میتوان با استفاده از اسلات nvigi::kGPTDataSlotSystem ایجاد کرد:
// تعریف نقش NPC در یک اعلان سیستم
std::string npcPrompt = "You are a helpful NPC named TJ in a fantasy game.";
nvigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());
nvigi::InferenceDataText systemPromptSlot(systemPromptData);
// تنظیم پارامترهای زمان اجرا
nvigi::GPTRuntimeParameters runtime{};
runtime.tokensToPredict = 200; // محدود کردن پیشبینی توکن به 200 توکن
runtime.interactive = true; // فعال کردن مکالمات چند نوبتی
std::vector<nvigi::InferenceDataSlot> slots = {
{nvigi::kGPTDataSlotSystem, &systemPromptSlot}
};
// زمینه استنتاج
nvigi::InferenceExecutionContext gptExecCtx{};
gptExecCtx.instance = gptInstance;
gptExecCtx.runtimeParameters = runtime;
gptExecCtx.inputs = slots.data();تعامل پویا بین بازیکن و شخصیت بازی را میتوان به صورت زیر مدیریت کرد:
std::string userInput = "What’s your name?"; // نمونه ورودی کاربر
nvigi::CpuData userInputData(userInput.length() + 1, userInput.c_str());
nvigi::InferenceDataText userInputSlot(userInputData);
slots = {{nvigi::kGPTDataSlotUser, &userInputSlot}};
gptExecCtx.inputs = slots.data();استنتاج را اجرا کنید و به صورت ناهمزمان به پاسخ رسیدگی کنید:
if (gptExecCtx.instance->evaluate(&gptExecCtx) == nvigi::kResultOk) {
std::cout << "Inference completed successfully!" << std::endl;
}هر نوبت از مکالمه از طریق اسلات ورودی nvigi::kGPTDataSlotUser پردازش میشود و زمینه را برای گفتگوی چند نوبتی حفظ میکند.
همچنین میتوانید یک تابع بازخوانی را برای گرفتن پاسخ شخصیت برای نمایش در بازی پیادهسازی کنید، که مثال آن در بخش بعدی نشان داده شده است.
فعال کردن زمانبندی GPU و ادغام رندرینگ
بارهای کاری هوش مصنوعی در بازیها در کنار وظایف رندرینگ اجرا میشوند، بنابراین زمانبندی مؤثر GPU برای حفظ نرخ فریم بسیار مهم است. NVIGI از CIG برای زمانبندی کارآمد بارهای کاری GPU استفاده میکند.
برای زمانبندی کارآمد گرافیک و محاسبه، NVIGI باید صف مستقیم D3D را که بازی شما برای گرافیک استفاده میکند، دریافت کند. ساختار D3D12Parameters تضمین میکند که NVIGI مستقیماً با خط لوله رندرینگ ادغام میشود و وظایف هوش مصنوعی را قادر میسازد تا به موازات اجرا شوند بدون اینکه بر عملکرد گرافیکی تأثیر بگذارند.
مثال کد زیر نحوه فعال کردن CIG را برای استنتاج هوش مصنوعی با استفاده از رابط NVIGI IHWICuda، با استفاده از پلاگین ASR به عنوان مثال نشان میدهد:
// فعال کردن محاسبه در گرافیک (CIG)
nvigi::IHWICuda* icig = nullptr;
if (nvigiGetInterface(nvigi::plugin::hwi::cuda::kId, &icig) != nvigi::kResultOk || !icig) {
std::cerr << "Failed to load CIG interface." << std::endl;
return;
}
// تنظیم پارامترهای D3D12
nvigi::D3D12Parameters d3d12Params{};
d3d12Params.device = myD3D12Device; // دستگاه D3D12 مورد استفاده برای رندرینگ
d3d12Params.queue = myD3D12CommandQueue; // صف دستور گرافیکی
// فعال کردن زمانبندی GPU هم برای استنتاج و هم برای رندرینگ
if (icig->enableComputeInGraphics(d3d12Params) != nvigi::kResultOk) {
std::cerr << "Failed to enable Compute-in-Graphics." << std::endl;
return;
}
std::cout << "Compute-in-Graphics enabled successfully." << std::endl;برای تنظیم زمانبندی GPU NVIGI در Unreal Engine 5 (UE5)، از رابط سختافزاری رندرینگ پویا جهانی (RHI) برای دسترسی به دستگاه D3D و صف دستور بازی استفاده کنید.
پیکربندی CIG در UE5 ساده است:
// کد خاص UE5 برای بازیابی منابع D3D12
#include "ID3D12DynamicRHI.h"
ID3D12DynamicRHI* RHI = nullptr;
if (GDynamicRHI && GDynamicRHI->GetInterfaceType() == ERHIInterfaceType::D3D12)
{
RHI = static_cast<ID3D12DynamicRHI*>(GDynamicRHI);
}
ID3D12CommandQueue* CmdQ = nullptr;
ID3D12Device* D3D12Device = nullptr;
if (RHI) {
CmdQ = RHI->RHIGetCommandQueue(); // دریافت صف دستور گرافیکی
int DeviceIndex = 0;
D3D12Device = RHI->RHIGetDevice(DeviceIndex); // دریافت دستگاه D3D12
}
// پیکربندی پارامترهای D3D12 برای IGI
nvigi::D3D12Parameters d3d12Params{};
d3d12Params.device = D3D12Device;
d3d12Params.queue = CmdQ;
// انتقال پارامترها به نمونههای IGI
vigi::CommonCreationParameters commonParams{};
commonParams.chain(d3d12Params);
// مثال: ایجاد یک نمونه ASR با CIG
vigi::ASRCreationParameters asrParams{};
asrParams.common = &commonParams;
vigi::InferenceInstance* asrInstance = nullptr;
iasr->createInstance(asrParams, &asrInstance);اجرای استنتاج
وظایف استنتاج در NVIGI شامل تنظیم یک زمینه مکالمه، پردازش ورودیهای کاربر و تولید پاسخها به صورت پویا است. مراحل زیر نحوه اجرای کارآمد وظایف استنتاج را در محیط بازی شما شرح میدهند.
برای اجرای استنتاج، باید یک زمینه استنتاج ایجاد کنید که شامل موارد زیر است:
- اسلاتهای ورودی: دادههای ورودی (متن کاربر، دادههای صوتی) را در قالبی که مدل میتواند پردازش کند، تهیه کنید.
- پارامترهای زمان اجرا: رفتار استنتاج را تعریف کنید، مانند تعداد توکنهایی که باید پیشبینی شوند یا تنظیمات تعاملی.
- مکانیسمهای بازخوانی: مشخص کنید که چگونه نتایج خروجی را مدیریت کنید.
زمینه استنتاج نحوه پردازش ورودیها و خروجیها را تعریف میکند. با فعال کردن حالت تعاملی و تهیه پارامترهای زمان اجرا شروع کنید:
// پیکربندی پارامترهای زمان اجرا برای GPT
nvigi::GPTRuntimeParameters runtime{};
runtime.tokensToPredict = 200; // پیشبینی حداکثر 200 توکن
runtime.interactive = true; // فعال کردن حالت تعاملی
// تنظیم زمینه استنتاج
vigi::InferenceExecutionContext gptExecCtx{};
gptExecCtx.instance = gptInstance; // استفاده از نمونه GPT ایجادشده قبلی
gptExecCtx.runtimeParameters = runtime;
gptExecCtx.callback = [](const nvigi::InferenceExecutionContext* execCtx, nvigi::InferenceExecutionState state, void* userData) {
if (state == nvigi::kInferenceExecutionStateDone && execCtx->outputs){
const nvigi::InferenceDataText* responseText = nullptr;
execCtx->outputs->findAndValidateSlot(nvigi::kGPTDataSlotResponse, &responseText);
if (responseText) {
std::cout << "NPC Response: " << responseText->getUtf8Text() << std::endl;
}
}
return state;
};
میتوانید مکالمه را با ارائه یک اعلان سیستم که شخصیت یا نقش NPC را تعریف میکند، شروع کنید. از اسلات nvigi::kGPTDataSlotSystem برای این منظور استفاده کنید:
// تنظیم زمینه مکالمه
std::string npcPrompt = "You are a helpful NPC in a fantasy game. Respond thoughtfully to player questions.";
vigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());
vigi::InferenceDataText systemPromptSlot(systemPromptData);
std::vector<nvigi::InferenceDataSlot> slots = {
{nvigi::kGPTDataSlotSystem, &systemPromptSlot} // تنظیم اعلان سیستم
};
gptExecCtx.inputs = slots.data();
gptExecCtx.numInputs = slots.size();
// اجرا برای مقداردهی اولیه زمینه مکالمه
if (gptExecCtx.instance->evaluate(&gptExecCtx) != nvigi::kResultOk) {
std::cerr << "Failed to initialize conversation context." << std::endl;
return;
}لیست پلاگینهای NVIGI موجود
امروز میتوانید با مدلهای گفتار و هوش زیر، چارچوبهای عامل را برای استنتاج روی دستگاه بسازید.
| پلاگین NVIGI | سختافزار استنتاج پشتیبانیشده | مدلهای پشتیبانیشده |
|---|---|---|
nvigi.plugin.asr.riva.cuda |
CUDA | Riva Speech-to-Text |
nvigi.plugin.gpt.trt.cuda |
CUDA, TensorRT | Megatron-GPT 20B, T5-220B |
nvigi.plugin.gpt.nemo.cuda |
CUDA, TensorRT | Mistral-7B-Instruct-v0.2 |
nvigi.plugin.gpt.ggml.cuda |
CUDA | Nemotron-4.5B-SteerLM-Instruct, MiniCPM-2B, Mistral-7B-Instruct-v0.2 |
nvigi.plugin.embed.ggml.cuda |
CUDA | E5-large-unsupervised |
این پلاگینها و مدلها نمونهای از امکانات قدرتمند و انعطافپذیر ارائه شده توسط NVIGI هستند و به توسعهدهندگان این امکان را میدهند تا تعاملات واقعاً غوطهور و پویا را در بازیهای خود ایجاد کنند.
نتیجهگیری
ادغام NVIDIA ACE با NVIGI یک تغییر دهنده بازی در توسعه بازی است و به توسعهدهندگان ابزارهایی را برای ایجاد شخصیتهای پویا، تعاملی و آگاه از زمینه ارائه میدهد. با استفاده از NVIGI، بازیها میتوانند بارهای کاری استنتاج هوش مصنوعی را به طور مؤثر مدیریت کنند، عملکرد بهینه را حفظ کرده و تجربههای جدید و جذابی را برای بازیکنان ارائه دهند. همانطور که مدلهای ACE روی دستگاه به تکامل خود ادامه میدهند، پتانسی ل و گردشهای کاری NVIGI امکانات هیجانانگیزی را برای آینده بازی با هوش مصنوعی ارائه میدهند.
اکنون میتوانید شروع به آزمایش این مدلها و APIها کنید. این امکانات در دسترس شما هستند:
- برای کسب اطلاعات بیشتر در مورد NVIDIA ACE، از NVIDIA ACE دیدن کنید.
- SDK استنتاج درون بازی NVIDIA (NVIGI) را از NVIDIA RTX In-Game Inferencing SDK بارگیری کنید.
- برای اطلاعات و پشتیبانی بیشتر، به انجمن NVIDIA In-Game Inferencing بپیوندید.