
درحالی که صنعت همچنان بر معیارهای دقت گسترده تمرکز دارد، ارزش واقعی کسبوکار در ثبت جزئیات مهمی است که برنامههای کاربردی هوش مکالمه را تقویت میکنند: اسمهای خاص که معنای خود را حفظ میکنند، حروف الفبای عددی که به درستی تأیید میشوند و قالببندی که معنای مورد نظر را در زبانهای مختلف منتقل میکند.
امروز، ما پیشرفتهای بیشتری را در بهترین خانواده مدل جهانی تبدیل گفتار به متن خود برای سه زبان مهم صنعتی ارائه میدهیم: انگلیسی، آلمانی و اسپانیایی. این یک بهبود نسبت به نسخه جهانی اکتبر 2024 ما از نظر تأخیر، دقت و پوشش زبان است.
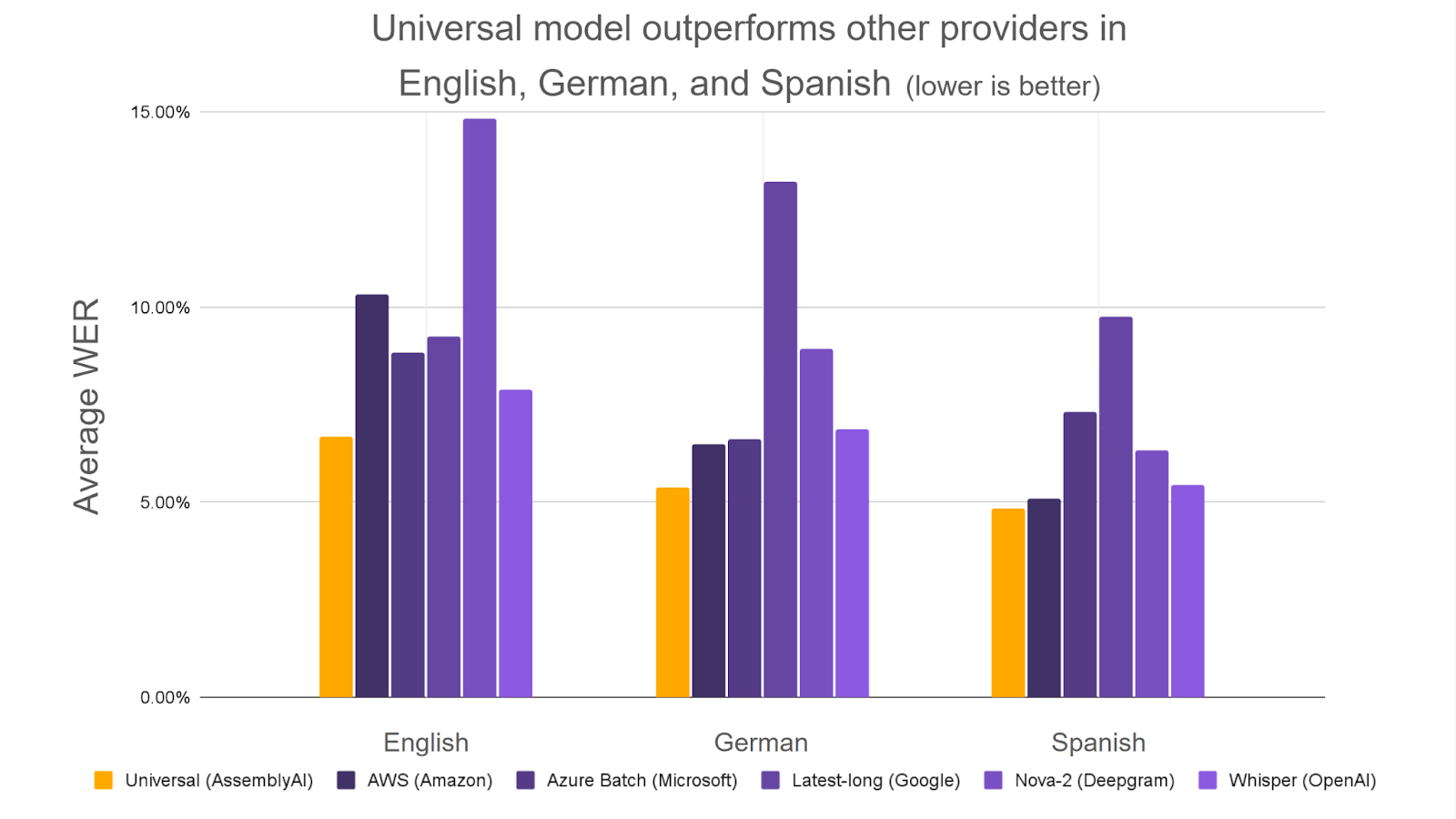
نمودار زیر نرخ خطای استاندارد Universal را در مقایسه با مدلهای پیشرو در بازار برای انگلیسی، آلمانی و اسپانیایی نشان میدهد و دقت پیشرو Universal را در هر سه زبان نشان میدهد:
علاوه بر این، این بهبودها در دقت با افزایش قابل توجهی در سرعت پردازش همراه است. آخرین نسخه جهانی ما به 27.4% سرعت بیشتر در زمان استنتاج برای اکثریت قریب به اتفاق فایلها (در صدک 95) دست مییابد و رونویسی سریعتر در مقیاس بزرگ را امکانپذیر میکند.
Universal فراتر از معیارهای استاندارد میرود تا چالشهای "مرحله آخر" در تشخیص گفتار را حل کند - جزئیات مهمی که رونویسیها را واقعاً برای برنامههای کاربردی تجاری مفید میکند. علاوه بر دقت استاندارد، پوشش زبان و بهبود سرعت پردازش برای همه زبانهای تحت پوشش که در بالا ذکر شد، ارتقاءهای جهانی امروز بهبودهای بیشتری را در این چالشهای مرحله آخر، به ویژه برای صدای انگلیسی به ارمغان میآورد.
بهبودهای "مرحله آخر" انگلیسی
در حالی که ارزیابیهای سنتی تبدیل گفتار به متن در درجه اول بر نرخ خطای کلمه تمرکز دارند، برنامههای کاربردی دنیای واقعی تقاضای بیشتری دارند: نام شرکتهای دقیق که از گردش کار تشدید عامل پشتیبانی میکنند، ایمیلهای قالببندی شده مناسب که پیگیریهای خودکار را امکانپذیر میکنند و مدیریت سازگار با اشاره به محصول که تجزیه و تحلیل فروش را تقویت میکند.
با تکیه بر عملکرد انگلیسی در کلاس جهانی Universal، ارتقاءهای امروز بهبودهای قابل توجهی را در این چالشهای مرحله آخر به ارمغان میآورد. مدل بهبودیافته ما موجودیتهای مهمی مانند نامها و آدرسهای ایمیل را دقیقتر از راهحلهای موجود در بازار ثبت و قالببندی میکند، که توسط آزمایشهای عملکرد جامع پشتیبانی میشود. در اینجا برخی از نکات برجسته آورده شده است:
- اسمهای خاص: 12.5% بهبود نسبی در دقت اسم خاص (PNER) از 15.06% به 13.17%، که از ثبت صحیح نامها، برندها و شرکتها اطمینان حاصل میکند.
- گفتار با لهجه: 5% بهبود نسبی در عملکرد در گفتار انگلیسی با لهجه (WER) از 11.4% به 10.8%، که عملکرد بهتری را در سبکهای گفتاری متنوع ارائه میدهد.
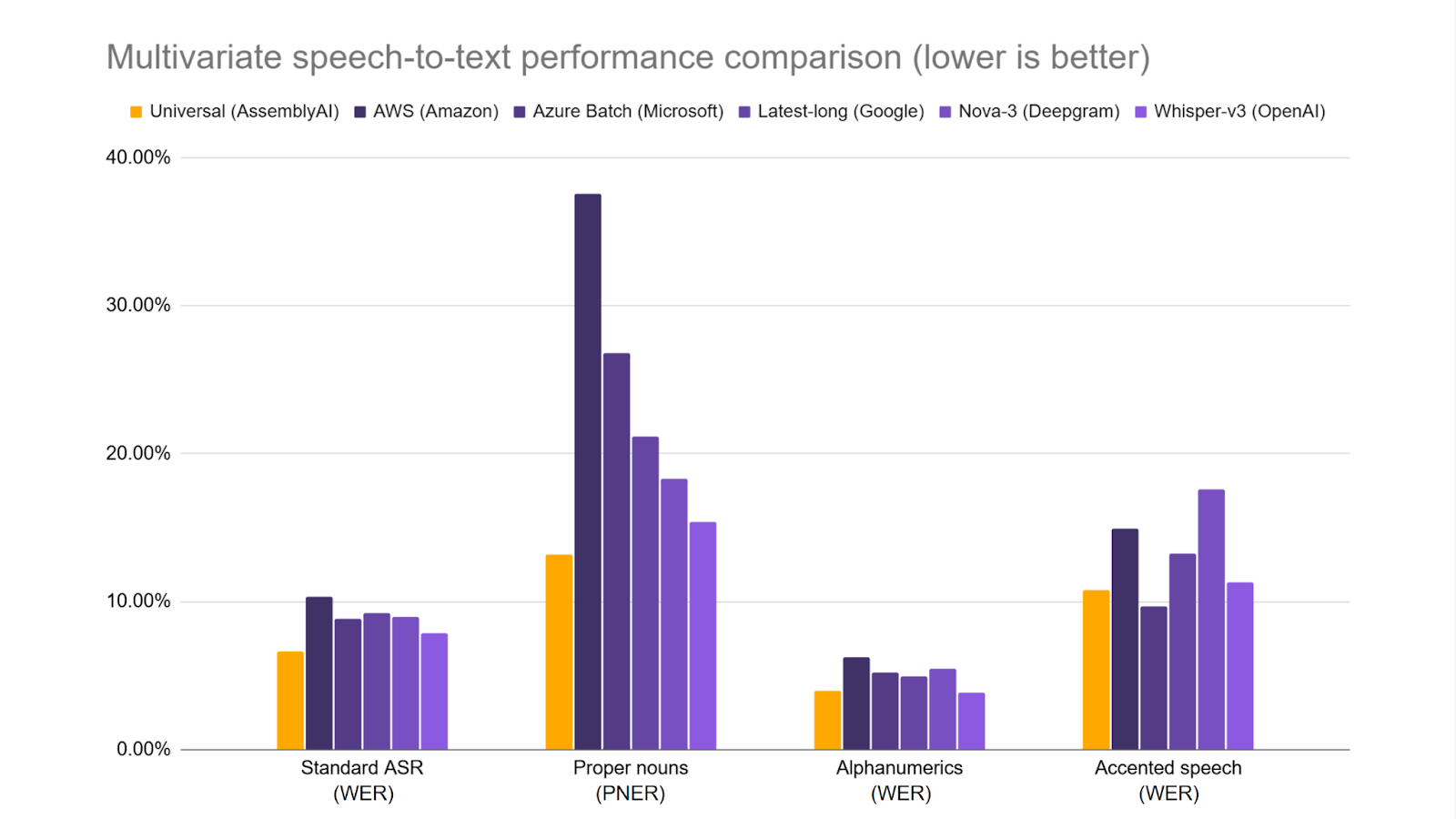
نمودار زیر Universal را با چندین مدل دیگر تبدیل گفتار به متن در معیارهای مختلف مقایسه میکند که مجموعاً یک معیار جامع از عملکرد مدل را تشکیل میدهند. در مقابل تمرکز صرف بر دقت ASR استاندارد تحلیلهای تک متغیره معمولی، مجموعه اندازهگیریهای نمایش داده شده در زیر ارزیابی میکند که یک مدل چقدر خوب از عهده موجودیتهای زبانی کلیدی برمیآید که در موارد استفاده در دنیای واقعی بسیار مهم هستند. هر مقدار نشان دهنده نرخ خطا است، بنابراین هر چه کمتر باشد بهتر است.
نمودار برای هر مدل نشان میدهد:
- ASR استاندارد: اندازهگیری نرخ خطای کلمه کلاسیک (WER)، که دقت کلی را بررسی میکند (ASR = تشخیص خودکار گفتار).
- دقت اسم خاص: نرخ خطای اسم خاص (PNER)، که معیاری است که توسط تیم تحقیقاتی ما ابداع شده است تا عملکرد مدل را به طور خاص بر روی اسمهای خاص بررسی کند.
- دقت الفبای عددی: نرخ خطای الفبای عددی، اندازهگیری شده توسط WER، که عملکرد مدل را در رشتههای الفبای عددی مانند شماره تلفن و آدرس ایمیل بررسی میکند.
- دقت گفتار با لهجه: نرخ خطای گفتار با لهجه، اندازهگیری شده توسط WER، که عملکرد مدل را در گفتار انگلیسی با لهجه بررسی میکند.
عملکرد قوی Universal در سراسر مجموعه معیارها، استحکام را در موارد استفاده عملی نشان میدهد.
به عنوان مثال، مراکز تماس برای ثبت دقیق اطلاعات تماس گیرنده مانند شماره تلفن و آدرس ایمیل، چه برای سرنخهای فروش ورودی و چه برای تماسهای خدمات مشتری، متکی هستند. عملکرد قوی Universal در الفبای عددی نشان میدهد که این ویژگیهای مهم به طور کامل در رونویسیهای تماس ثبت میشوند.
حوزههای دیگر مانند مربیگری فروش از عملکرد قوی Universal در اسمهای خاص بهره میبرند و اطمینان حاصل میکنند که موجودیتهایی مانند نامها، شرکتها، محصولات و مکانها به طور دقیق ثبت میشوند. این دقت نه تنها برای بینشهای تاکتیکی مانند تجزیه و تحلیل تعاملات مشتری، ردیابی اشارههای رقابتی و اندازهگیری آگاهی از برند، بلکه برای مبانی اساسی ایجاد روابط واقعی از طریق توجه به جزئیات بسیار مهم است.
و دقت قالببندی متن قوی Universal، رونویسیهای بسیار خوانایی را به همراه دارد که برای هر برنامهای مهم است - یک مثال را در زیر بررسی کنید (منبع صوتی).
به نسخه دیگری از تلویزیون مسافر خوش آمدید. امروز ما در پل آرتور راونل جونیور هستیم که در اینجا واقع شده است. این پل در سال 2005 افتتاح شد و در حال حاضر طولانیترین پل کابلی در نیمکره غربی است. این طراحی دارای دو برج الماسی شکل است که رودخانه کوپر را در بر میگیرد و مرکز شهر چارلستون را به Mount Pleasant متصل میکند. مسیرهای دوچرخهسواری و پیادهروی مناظر بینظیری از بندر را ارائه میدهند و مکانی عالی برای تماشای طلوع یا غروب خورشید است. برای پیادهروی یا دوچرخهسواری روی پل، میتوانید در سمت مرکز شهر در اینجا یا در سمت Mount Pleasant در Memorial Waterfront Park پارک کنید. برای کسب اطلاعات بیشتر در مورد پل آرتور راونل جونیور و سایر فعالیتهای سرگرمکننده در چارلستون، SC. از وبسایت ما به آدرس travelerofcharleston.com دیدن کنید یا برنامه تلفن همراه رایگان ما را برای گشت و گذار در چارلستون، SC دانلود کنید.
نحوه استفاده از Universal برای تبدیل گفتار به متن
میتوانید Universal را بلافاصله در Playground ما امتحان کنید - فقط یک فایل صوتی انگلیسی، آلمانی یا اسپانیایی ارسال کنید و ویژگیهای خود را انتخاب کنید تا نتایج Universal را روی دادههای خود مشاهده کنید.
همچنین میتوانید از Universal از طریق API ما استفاده کنید. برای دریافت کلید API رایگان خود ثبت نام کنید و سپس API ما را به زبان و محیط دلخواه خود فراخوانی کنید. به عنوان مثال، در اینجا نحوه استفاده از Universal در پایتون با SDK پایتون ما آمده است. Universal مدل پیشفرض است، اما میتوان آن را به طور صریح با تعیین لایه مدل best تنظیم کرد. علاوه بر این، میتوانید مستقیماً یک language_code تنظیم کنید یا از تشخیص خودکار زبان ما استفاده کنید:
# pip install assemblyai
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
audio_file = "https://assembly.ai/sports_injuries.mp3"
config = aai.TranscriptionConfig(
language_code="en", # "de", "es"
speech_model=aai.SpeechModel.best
)
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(audio_file, config)
print(transcript.text)
میتوانید از هر فایل راه دور در دسترس عموم یا یک فایل محلی استفاده کنید. علاوه بر استفاده از SDKهای ما، میتوانید مستقیماً API ما را فراخوانی کنید:
curl -X POST https://api.assemblyai.com/v2/transcript \
-H "Authorization: your-api-key" \
-H "Content-Type: application/json" \
-d '{"audio_url": "https://assembly.ai/sports_injuries.mp3"}'
علاوه بر این، میتوانید هر یک از ویژگیهای دیگر ما را مانند برچسبهای بلندگو به طور معمول مشخص کنید. برای کسب اطلاعات بیشتر در مورد استفاده از Universal و سایر ویژگیهای موجود ما، اسناد ما را بررسی کنید یا برای تجزیه و تحلیل دقیقتر معیارها، صفحه معیارهای ما را بررسی کنید.