گرافهای دانش (KGs) بنیان برنامههای کاربردی هوش مصنوعی هستند، اما ناقص و پراکنده هستند که بر اثربخشی آنها تأثیر میگذارد. گرافهای دانش تثبیتشده مانند DBpedia و Wikidata فاقد روابط اساسی موجودیت هستند، که سودمندی آنها را در تولید تقویتشده با بازیابی (RAG) و سایر وظایف یادگیری ماشین کاهش میدهد. روشهای استخراج سنتی احتمالاً گرافهای پراکندهای با اتصالات مهم غایب یا نمایشهای پر سروصدا و اضافی ارائه میدهند. بنابراین، به دست آوردن دانش ساختاریافته با کیفیت بالا از متن بدون ساختار دشوار است. غلبه بر این چالشها برای امکان بازیابی دانش، استدلال و بینش بهبودیافته با کمک هوش مصنوعی حیاتی است.
روشهای پیشرفته برای استخراج KGs از متن خام، استخراج اطلاعات باز (OpenIE) و GraphRAG هستند. OpenIE، یک تکنیک تجزیه وابستگی، سهگانههای ساختاریافته (فاعل، رابطه، مفعول) تولید میکند، اما گرههای بسیار پیچیده و اضافی تولید میکند و انسجام را کاهش میدهد. GraphRAG، که بازیابی مبتنی بر گراف و مدلهای زبانی را ترکیب میکند، پیوند موجودیت را افزایش میدهد، اما گرافهای متراکم متصل تولید نمیکند، و فرآیندهای استدلال پاییندستی را محدود میکند. هر دو تکنیک از سازگاری پایین تفکیک موجودیت، پراکندگی در اتصال و تعمیمپذیری ضعیف رنج میبرند، و آنها را برای استخراج KG با کیفیت بالا غیر مؤثر میکند.
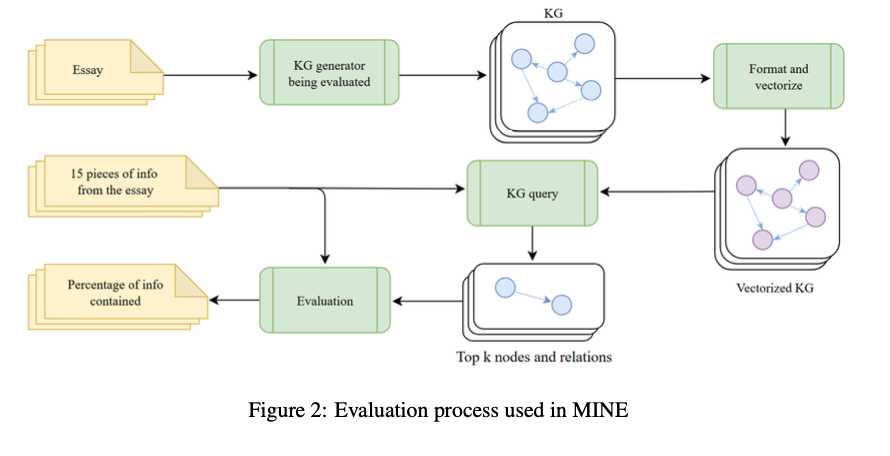
محققان دانشگاه استنفورد، دانشگاه تورنتو و FAR AI، KGGen را معرفی میکنند، یک ژنراتور متن به KG جدید که از مدلهای زبانی و الگوریتمهای خوشهبندی برای استخراج دانش ساختاریافته از متن ساده استفاده میکند. برخلاف روشهای قبلی، KGGen یک روش خوشهبندی تکراری مبتنی بر LM را معرفی میکند که با ادغام موجودیتهای مترادف و گروهبندی روابط، گراف استخراجشده را بهبود میبخشد. این باعث افزایش پراکندگی و افزونگی میشود و یک KG منسجمتر و متصلتر ارائه میدهد. KGGen همچنین MINE (معیار اطلاعات در گرهها و لبهها) را معرفی میکند، اولین معیار برای عملکرد استخراج متن به KG، که امکان اندازهگیری استاندارد روشهای استخراج را فراهم میکند.
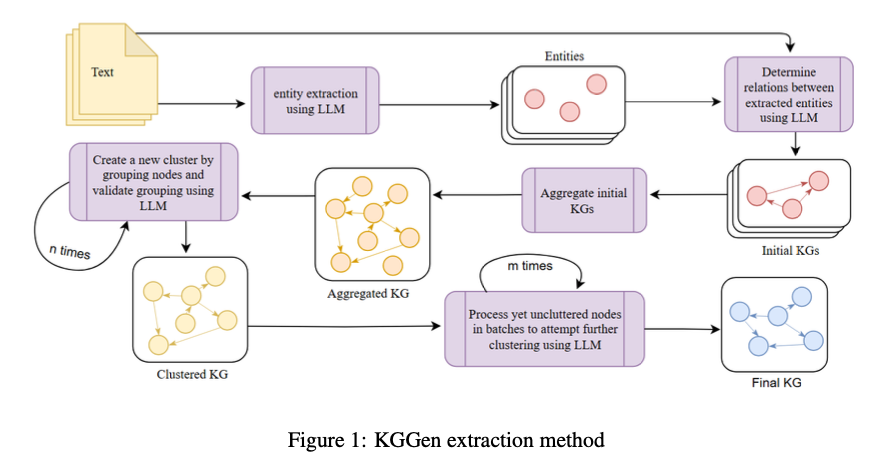
KGGen از طریق یک بسته پایتون ماژولار با ماژولهایی برای استخراج موجودیت و رابطه، تجمیع و خوشهبندی موجودیت و لبه عمل میکند. ماژول استخراج موجودیت و رابطه از GPT-4o برای به دست آوردن سهگانههای ساختاریافته (فاعل، گزاره، مفعول) از متن بدون ساختار استفاده میکند. ماژول تجمیع سهگانههای استخراجشده از منابع مختلف را در یک گراف دانش یکپارچه (KG) ترکیب میکند، از این رو یک نمایش همگن از موجودیتها را تضمین میکند. ماژول خوشهبندی موجودیت و لبه از یک الگوریتم خوشهبندی تکراری برای رفع ابهام از موجودیتهای مترادف، خوشهبندی لبههای مشابه و افزایش اتصال گراف استفاده میکند. از طریق اجرای محدودیتهای سختگیرانه بر روی مدل زبانی با استفاده از DSPy، KGGen دستیابی به استخراجهای ساختاریافته و با دقت بالا را امکانپذیر میکند. گراف دانش خروجی با اتصال متراکم، ارتباط معنایی و بهینهسازی برای اهداف هوش مصنوعی متمایز میشود.
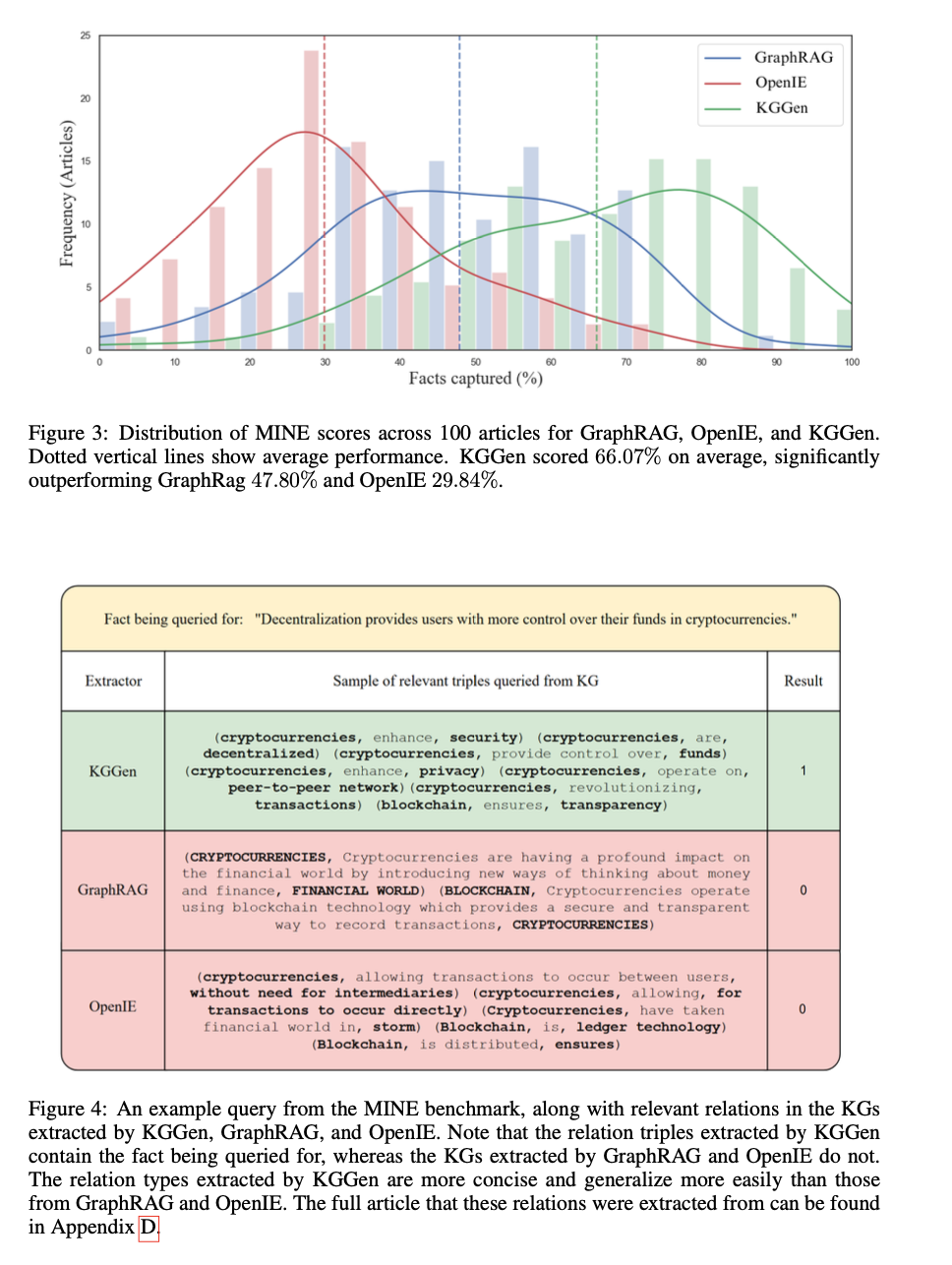
نتایج معیار نشاندهنده موفقیت این روش در استخراج دانش ساختاریافته از منابع متنی است. KGGen نرخ دقت 66.07٪ را به دست میآورد، که به طور قابل توجهی بیشتر از GraphRAG با 47.80٪ و OpenIE با 29.84٪ است. این سیستم قابلیت استخراج و ساختاربندی دانش بدون افزونگی و افزایش اتصال و انسجام را تسهیل میکند. تجزیه و تحلیل مقایسهای بهبود 18 درصدی در دقت استخراج نسبت به روشهای موجود را تأیید میکند، و توانایی آن را برای تولید گرافهای دانش خوشساختار برجسته میکند. آزمایشها همچنین نشان میدهد که گرافهای تولیدشده متراکمتر و آموزندهتر هستند، و آنها را به ویژه در زمینه وظایف بازیابی دانش و استدلال مبتنی بر هوش مصنوعی مناسب میسازد.
به طور خلاصه، KGGen یک رویکرد جدید است که به طور قابل توجهی استخراج گراف دانش از متن را با استفاده از مدلهای زبانی و تکنیکهای خوشهبندی پیشرفته بهبود میبخشد. KGGen به لطف رویکرد خوشهبندی تکراری و معرفی معیار MINE، نمایشهای گرافی دقیقتر، منسجمتر و غنیتر را در مقایسه با روشهای مرسوم امکانپذیر میکند. KGGen به عنوان یک ابزار ارزشمند در بسیاری از برنامههای کاربردی هوش مصنوعی که به دانش ساختاریافته با کیفیت بالا نیاز دارند، ظاهر میشود.