
حوزه مدلهای زبانی بزرگ مدتهاست که تحت سلطه روشهای اتورگرسیو بوده است که متن را به طور متوالی از چپ به راست پیشبینی میکنند. در حالی که این رویکردها سیستمهای هوش مصنوعی توانمند امروزی را تقویت میکنند، با محدودیتهای اساسی در کارایی محاسباتی و استدلال دوطرفه مواجه هستند. یک تیم تحقیقاتی از چین اکنون این فرض را به چالش کشیده است که مدلسازی اتورگرسیو تنها راه دستیابی به تواناییهای زبانی شبیه انسان است و یک معماری مبتنی بر انتشار نوآورانه به نام LLaDA را معرفی کرده است که نحوه پردازش اطلاعات توسط مدلهای زبانی را دوباره تصور میکند.
مدلهای زبانی فعلی از طریق پیشبینی کلمه بعدی عمل میکنند و با افزایش اندازه پنجرههای متن، محاسبات پیچیدهتری را میطلبند. این ماهیت متوالی باعث ایجاد گلوگاههایی در سرعت پردازش میشود و اثربخشی در وظایفی که نیاز به استدلال معکوس دارند را محدود میکند. به عنوان مثال، مدلهای اتورگرسیو سنتی از نفرین معکوس رنج میبرند - پدیدهای که در آن مدلهایی که برای پیشبینی توکن بعدی آموزش داده شدهاند، با وظایف منطقی معکوس دست و پنجه نرم میکنند. تکمیل شعر را در نظر بگیرید:
- وظیفه مستقیم (قدرت اتورگرسیو): با توجه به提示 "گلها قرمز هستند"، مدلها به راحتی با "بنفشها آبی هستند" ادامه میدهند.
- وظیفه معکوس (ضعف اتورگرسیو): با توجه به "بنفشها آبی هستند"، همین مدلها اغلب نمیتوانند "گلها قرمز هستند" را به عنوان خط قبلی به خاطر بیاورند.
این جهتگیری ناشی از آموزش آنها برای پیشبینی متن دقیقاً از چپ به راست است. در حالی که مدلهای زبانی پوشانده شده (مانند BERT) وجود دارند، اما به طور سنتی از نسبتهای پوشش ثابت استفاده میکنند و قابلیتهای تولیدی آنها را محدود میکنند. محققان LLaDA (انتشار زبان بزرگ با پوشش) را پیشنهاد میکنند که یک استراتژی پوشش پویا را در مراحل انتشار برای غلبه بر این محدودیتها پیادهسازی میکند (در شکل 2 نشان داده شده است). برخلاف مدلهای اتورگرسیو، LLaDA توکنها را به طور موازی از طریق یک چارچوب دوطرفه پردازش میکند و روابط متنی را در تمام جهات به طور همزمان یاد میگیرد.
معماری LLaDA از یک ترانسفورماتور بدون پوشش علّی استفاده میکند که از طریق دو مرحله آموزش داده میشود:
- پیشآموزش: مدل یاد میگیرد قطعات متنی که به طور تصادفی پوشانده شدهاند را در 2.3 تریلیون توکن بازسازی کند. تصور کنید که یک نسخه خطی آسیبدیده را تعمیر میکنید که در آن کلمات به طور غیرقابل پیشبینی ناپدید میشوند - LLaDA پر کردن شکافها را به هر ترتیبی تمرین میکند. به عنوان مثال:
- با یک جمله پوشانده شده شروع کنید: "[پوشش] قرمز هستند، [پوشش] آبی هستند."
- ابتدا "بنفش" را برای جای خالی دوم پیشبینی کنید، سپس "گلها" را برای اولی.
- چرخههای مکرر پوشش/رفع پوشش، جهتگیری را از بین میبرند.
- تنظیم دقیق نظارت شده: مدل با پوشاندن تنها بخش پاسخ، با جفتهای دستورالعمل-پاسخ سازگار میشود و بهبودهای خاص وظیفه را در حالی که درک دوطرفه را حفظ میکند، امکانپذیر میکند.
در طول تولید، LLaDA با فیلدهای خروجی کاملاً پوشانده شده شروع میکند و به طور مکرر پیشبینیها را از طریق پوشش مجدد مبتنی بر اطمینان اصلاح میکند:
- در هر مرحله انتشار، مدل تمام توکنهای پوشانده شده را به طور همزمان پیشبینی میکند.
- پیشبینیهای با اطمینان پایین (به عنوان مثال، کلمات نامشخص در خط افتتاحیه یک شعر) برای ارزیابی مجدد دوباره پوشانده میشوند.
- این فرآیند "بازپخت معنایی" تکرار میشود تا زمانی که متن منسجمی ظاهر شود.
- دستیابی به دقت 42% در وظایف تکمیل شعر معکوس در مقابل 32% GPT-4، در حالی که برابری در تولید مستقیم را حفظ میکند.
- عملکرد ثابتی را در وظایف پرسش و پاسخ معکوس نشان داد (به عنوان مثال، "مادر تام کروز کیست؟" در مقابل "پسر مری لی پفیفر کیست؟")، جایی که مدلهای اتورگرسیو اغلب با شکست مواجه میشوند.
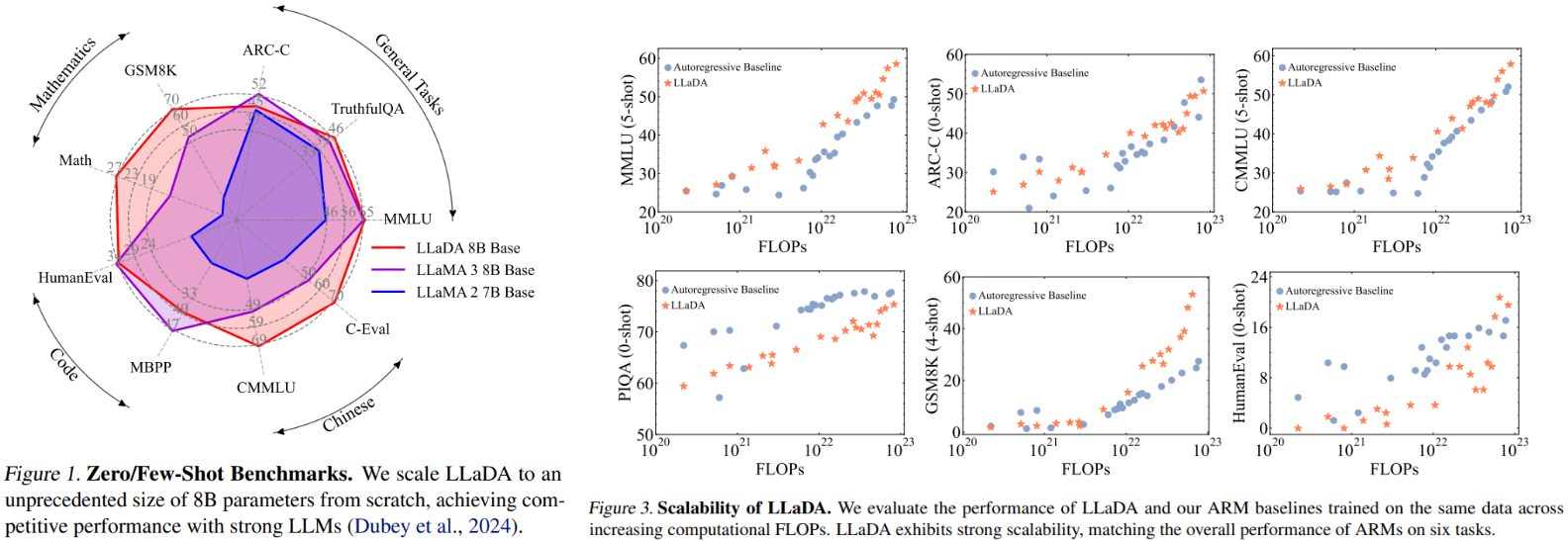
ارزیابیهای عملکرد قابلیتهای شگفتانگیزی را نشان میدهد. هنگامی که LLaDA به 8 میلیارد پارامتر مقیاس میشود، با مدلهای اتورگرسیو هم اندازه مانند LLaMA2-7B در 15 معیار برابری میکند یا از آن فراتر میرود و در استدلال ریاضی (GSM8K) و وظایف چینی برتری دارد. نکته مهم این است که بر نفرین معکوس غلبه میکند:
این مدل همچنین مقیاسبندی کارآمدی را نشان میدهد - هزینههای محاسباتی به طور قابل مقایسهای با معماریهای سنتی با وجود رویکرد جدید آن رشد میکنند. به طور خاص، در وظایفی مانند MMLU و GSM8K، LLaDA مقیاسپذیری قویتری را نیز نشان میدهد.
به طور خلاصه، این پیشرفت نشان میدهد که قابلیتهای کلیدی زبان از اصول تولیدی اساسی ناشی میشوند، نه تنها طرحهای اتورگرسیو. در حالی که پیادهسازیهای فعلی کمی در وظایفی مانند MMLU عقب هستند (احتمالاً به دلیل تغییرات کیفیت داده)، LLaDA مدلهای انتشار را به عنوان جایگزینهای مناسب تثبیت میکند. این تحقیق درها را به روی تولید موازی و استدلال دوطرفه باز میکند، اگرچه چالشهایی در بهینهسازی استنتاج و همسویی با ترجیحات انسانی باقی میماند. همانطور که این حوزه این جایگزینها را بررسی میکند، ممکن است شاهد مراحل اولیه یک تغییر پارادایم در نحوه پردازش زبان توسط ماشینها باشیم - مدلی که در آن مدلها به جای محدود شدن به پیشبینی خطی، "به طور کلنگر فکر میکنند".