مدلهای زبانی بزرگ چندوجهی (MLLM) به دلیل توانایی خود در انجام وظایف پیچیده شامل ادغام دید، زبان و صدا، توجه قابل توجهی را به خود جلب کردهاند. با این حال، آنها فاقد همترازی جامعی فراتر از تنظیم دقیق نظارتشده (SFT) هستند. مدلهای پیشرفته فعلی اغلب مراحل همترازی دقیقی را دور میزنند و جنبههای مهمی مانند صحت، ایمنی و همترازی ترجیحات انسانی را به طور ناکافی مورد توجه قرار میدهند. رویکردهای موجود فقط حوزههای خاصی مانند کاهش توهم یا بهبود مکالمات را هدف قرار میدهند و از بهبود عملکرد و قابلیت اطمینان کلی مدل باز میمانند. این تمرکز محدود این سوال را مطرح میکند که آیا همترازی ترجیحات انسانی میتواند MLLMها را در طیف وسیعتری از وظایف بهبود بخشد یا خیر.
سالهای اخیر شاهد پیشرفتهای چشمگیری در MLLMها بودهایم که بر اساس معماریهای پیشرفته LLM مانند GPT، LLaMA، Alpaca، Vicuna و Mistral ساخته شدهاند. این مدلها از طریق رویکردهای آموزش سرتاسری تکامل یافتهاند و وظایف چندوجهی پیچیدهای را شامل همترازی متن-تصویر، استدلال و پیروی از دستورالعملها انجام میدهند. چندین MLLM متنباز، از جمله Otter، mPLUG-Owl، LLaVA، Qwen-VL و VITA، برای رسیدگی به چالشهای اساسی چندوجهی ظهور کردهاند. با این حال، تلاشهای همترازی محدود باقی مانده است. در حالی که الگوریتمهایی مانند Fact-RLHF و LLAVACRITIC نویدبخش کاهش توهمات و بهبود تواناییهای مکالمه بودهاند، اما قابلیتهای کلی را افزایش ندادهاند. چارچوبهای ارزیابی مانند MME، MMBench و Seed-Bench برای ارزیابی این مدلها توسعه یافتهاند.
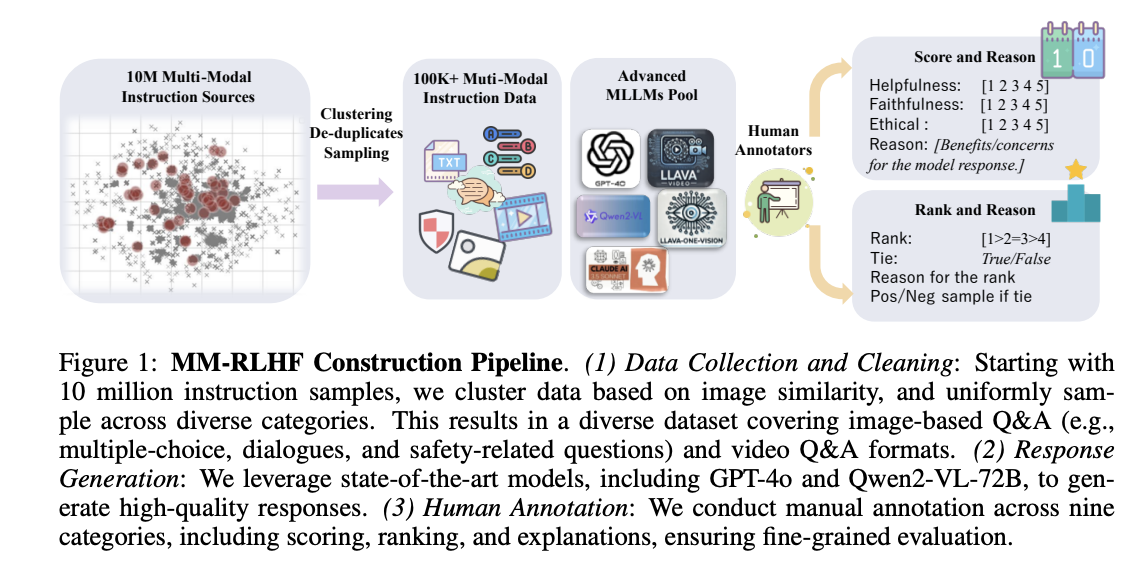
محققان KuaiShou، CASIA، NJU، USTC، PKU، Alibaba و Meta AI، رویکردی نوآورانه به نام MM-RLHF را پیشنهاد کردهاند که دارای مجموعه دادهای جامع از 120 هزار جفت مقایسه ترجیحی است که توسط انسانها با دقت بالایی حاشیهنویسی شده است. این مجموعه داده نشاندهنده پیشرفت قابل توجهی از نظر اندازه، تنوع و کیفیت حاشیهنویسی در مقایسه با منابع موجود است. این روش دو نوآوری کلیدی را معرفی میکند: یک مدل پاداش مبتنی بر نقد که قبل از امتیازدهی به خروجیها، نقدهای مفصلی تولید میکند، و مقیاسبندی پاداش پویا که وزن نمونهها را بر اساس سیگنالهای پاداش بهینه میکند. این امر هم تفسیرپذیری تصمیمات مدل و هم کارایی فرآیند همترازی را افزایش میدهد و محدودیتهای مکانیسمهای پاداش اسکالر سنتی را در زمینههای چندوجهی برطرف میکند.
پیادهسازی MM-RLHF شامل یک فرآیند پیچیده آمادهسازی و فیلتر کردن دادهها در سه حوزه اصلی است: درک تصویر، درک ویدیو و ایمنی چندوجهی. جزء درک تصویر دادهها را از منابع متعددی از جمله LLaVA-OV، VLfeedback و LLaVA-RLHF ادغام میکند و دیالوگهای چند نوبتی را به فرمت تک نوبتی تبدیل میکند. این گردآوری منجر به بیش از 10 میلیون نمونه دیالوگ میشود که وظایف متنوعی از مکالمه اساسی تا استدلال پیچیده را پوشش میدهد. فرآیند فیلتر کردن دادهها از وزنهای نمونهبرداری از پیش تعریفشدهای استفاده میکند که به سه نوع طبقهبندی میشوند: سوالات چند گزینهای برای آزمایش استدلال و ادراک، سوالات متنی طولانی برای ارزیابی تواناییهای مکالمه و سوالات متنی کوتاه برای تجزیه و تحلیل تصویر اساسی.
ارزیابی MM-RLHF و MM-DPO نشان میدهد که هنگام اعمال بر روی مدلهایی مانند LLaVA-OV-7B، LLaVA-OV-0.5B و InternVL-1B، بهبودهای قابل توجهی در ابعاد مختلف حاصل میشود. تواناییهای مکالمه بیش از 10 درصد بهبود یافته است، در حالی که رفتارهای ناایمن حداقل 50 درصد کاهش یافته است. مدلهای همتراز شده نتایج بهتری را در کاهش توهم، استدلال ریاضی و درک چند تصویری نشان میدهند، حتی بدون دادههای آموزشی خاص برای برخی از وظایف. با این حال، تغییرات خاص مدل مشاهده میشود، به طوری که مدلهای مختلف به تنظیمات ابرپارامترهای متمایز برای عملکرد بهینه نیاز دارند. همچنین، وظایف با وضوح بالا به دلیل محدودیتهای مجموعه داده و استراتژیهای فیلتر کردن که بهینهسازی وضوح را هدف قرار نمیدهند، دستاوردهای محدودی را نشان میدهند.
در این مقاله، محققان MM-RLHF، یک مجموعه داده و رویکرد همترازی را معرفی کردند که پیشرفت قابل توجهی در توسعه MLLM نشان میدهد. برخلاف رویکردهای خاص وظیفه قبلی، این روش رویکردی جامع برای بهبود عملکرد مدل در ابعاد مختلف اتخاذ میکند. دانه بندی حاشیهنویسی غنی مجموعه داده، از جمله نمرات هر بعد و منطق رتبهبندی، پتانسیل استفاده نشدهای را برای توسعه آینده ارائه میدهد. جهتگیریهای تحقیقاتی آینده بر استفاده از این دانه بندی از طریق تکنیکهای بهینهسازی پیشرفته، رسیدگی به محدودیتهای دادههای با وضوح بالا و گسترش مجموعه داده از طریق روشهای نیمه خودکار متمرکز خواهد بود، که به طور بالقوه پایهای برای چارچوبهای یادگیری چندوجهی قویتر ایجاد میکند.