مقاله "یک مدل بنیادین فقط-رمزگشا برای پیشبینی سریهای زمانی" در ICML 2024 پذیرفته شده است و نمودارها برای نمایش آخرین نتایج بهروزرسانی شدهاند. این مدل اکنون در مخازن HuggingFace و GitHub ما در دسترس است.
TimesFM یک مدل پیشبینیکننده است که بر روی مجموعه دادههای سری زمانی بزرگ حاوی ۱۰۰ میلیارد نقطه داده واقعی پیشآموزش دیده است و عملکرد چشمگیری در یادگیری بدون نمونه (zero-shot) بر روی معیارهای عمومی مختلف از دامنهها و دقتهای متفاوت از خود نشان میدهد.
پیشبینی سریهای زمانی در حوزههای مختلفی مانند خردهفروشی، مالی، تولید، مراقبتهای بهداشتی و علوم طبیعی کاربرد گستردهای دارد. برای مثال، در موارد استفاده خردهفروشی مشاهده شده است که بهبود دقت پیشبینی تقاضا میتواند هزینههای موجودی را به میزان قابل توجهی کاهش داده و درآمد را افزایش دهد. مدلهای یادگیری عمیق (DL) به عنوان یک رویکرد محبوب برای پیشبینی دادههای سری زمانی غنی و چند متغیره ظاهر شدهاند، زیرا ثابت کردهاند که در تنظیمات مختلف عملکرد خوبی دارند (به عنوان مثال، مدلهای DL در رقابت M5 عملکرد خوبی از خود نشان دادند).
در همین حال، پیشرفتهای سریعی در مدلهای زبان بنیادین بزرگ مورد استفاده برای وظایف پردازش زبان طبیعی (NLP) مانند ترجمه، تولید مبتنی بر بازیابی (retrieval-augmented generation) و تکمیل کد هوشمند حاصل شده است. این مدلها بر روی مقادیر عظیمی از دادههای متنی برگرفته از منابع مختلفی مانند Common Crawl و کدهای متنباز آموزش میبینند که به آنها اجازه میدهد الگوهای موجود در زبانها را شناسایی کنند. این امر آنها را به ابزارهای یادگیری بدون نمونه (zero-shot) بسیار قدرتمندی تبدیل میکند؛ به عنوان مثال، هنگامی که با بازیابی ترکیب میشوند، میتوانند به سؤالات مربوط به رویدادهای جاری پاسخ دهند و آنها را خلاصه کنند.
با وجود اینکه پیشبینیکنندههای مبتنی بر DL عمدتاً بهتر از روشهای سنتی عمل میکنند و پیشرفتهایی در کاهش هزینههای آموزش و استنتاج صورت گرفته است، اما با چالشهایی روبرو هستند: اکثر معماریهای DL قبل از اینکه مشتری بتواند مدل را بر روی یک سری زمانی جدید آزمایش کند، به چرخههای طولانی و پیچیده آموزش و اعتبارسنجی نیاز دارند. در مقابل، یک مدل بنیادین برای پیشبینی سریهای زمانی میتواند پیشبینیهای خارج از جعبه (out-of-the-box) مناسبی را برای دادههای سری زمانی دیده نشده بدون آموزش اضافی ارائه دهد، که به کاربران این امکان را میدهد تا بر روی بهبود پیشبینیها برای وظیفه نهایی واقعی مانند برنامهریزی تقاضای خردهفروشی تمرکز کنند.
در همین راستا، در مقاله "یک مدل بنیادین فقط-رمزگشا برای پیشبینی سریهای زمانی"، که در ICML 2024 پذیرفته شده است، ما TimesFM را معرفی میکنیم؛ یک مدل پیشبینیکننده واحد که بر روی مجموعه دادههای سری زمانی بزرگ حاوی ۱۰۰ میلیارد نقطه داده واقعی پیشآموزش دیده است. در مقایسه با جدیدترین مدلهای زبان بزرگ (LLM)، TimesFM بسیار کوچکتر است (۲۰۰ میلیون پارامتر)، با این حال نشان میدهیم که حتی در چنین مقیاسی، عملکرد یادگیری بدون نمونه (zero-shot) آن بر روی مجموعههای داده دیده نشده مختلف با دامنهها و دقتهای زمانی متفاوت، نزدیک به رویکردهای نظارت شده پیشرفتهای است که به طور صریح بر روی این مجموعههای داده آموزش دیدهاند. برای دسترسی به مدل، لطفاً به مخازن HuggingFace و GitHub ما مراجعه کنید.

یک مدل بنیادین فقط-رمزگشا برای پیشبینی سریهای زمانی
مدلهای زبان بزرگ (LLM) معمولاً به صورت فقط-رمزگشا (decoder-only) آموزش میبینند که شامل سه مرحله است. ابتدا، متن به زیرواژههایی به نام توکن تقسیم میشود. سپس، توکنها به لایههای ترانسفورمر علّی (causal transformer) انباشته شده (stacked) وارد میشوند که خروجی متناظر با هر توکن ورودی را تولید میکنند (این لایهها نمیتوانند به توکنهای آینده توجه کنند). در نهایت، خروجی متناظر با توکن i-ام، تمام اطلاعات توکنهای قبلی را خلاصه کرده و توکن (i+1)-ام را پیشبینی میکند. در طول استنتاج، LLM خروجی را به صورت توکن به توکن تولید میکند. به عنوان مثال، هنگامی که با "پایتخت فرانسه کجاست؟" مواجه میشود، ممکن است توکن "پایتخت" را تولید کند، سپس بر اساس "پایتخت فرانسه کجاست؟ پایتخت" توکن بعدی "فرانسه" را تولید کند و به همین ترتیب تا زمانی که پاسخ کامل را تولید کند: "پایتخت فرانسه پاریس است."
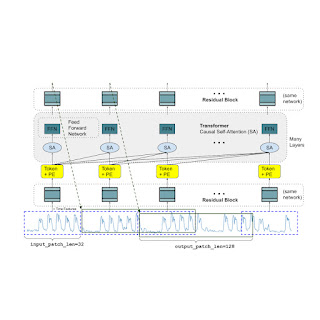
یک مدل بنیادین برای پیشبینی سریهای زمانی باید با طول زمینه (آنچه مشاهده میکنیم) و افق (آنچه از مدل میخواهیم پیشبینی کند) متغیر سازگار شود، در حالی که ظرفیت کافی برای کدگذاری تمام الگوها از یک مجموعه داده پیشآموزشی بزرگ را نیز داشته باشد. مشابه LLMها، ما از لایههای ترانسفورمر انباشته شده (توجه خودکار و لایههای پیشخور (feedforward)) به عنوان بلوکهای اصلی سازنده مدل TimesFM استفاده میکنیم. در زمینه پیشبینی سریهای زمانی، ما یک پچ (گروهی از نقاط زمانی پیوسته) را به عنوان یک توکن در نظر میگیریم که توسط یک کار اخیر در پیشبینی با افق بلند محبوب شده است. در این صورت، وظیفه این است که پچ (i+1)-ام نقاط زمانی را با توجه به خروجی i-ام در انتهای لایههای ترانسفورمر انباشته شده، پیشبینی کنیم.
با این حال، چندین تفاوت کلیدی با مدلهای زبان وجود دارد. اولاً، ما به یک بلوک پرِسپترون چند لایه (multilayer perceptron) با اتصالات باقیمانده (residual connections) نیاز داریم تا یک پچ از سری زمانی را به یک توکن تبدیل کند که بتواند به همراه کدگذاریهای موقعیتی (positional encodings - PE) به لایههای ترانسفورمر وارد شود. برای این منظور، از یک بلوک باقیمانده مشابه کار قبلی خود در پیشبینی با افق بلند استفاده میکنیم. ثانیاً، در انتهای دیگر، یک توکن خروجی از ترانسفورمر انباشته شده میتواند برای پیشبینی طول بیشتری از نقاط زمانی بعدی نسبت به طول پچ ورودی استفاده شود، یعنی طول پچ خروجی میتواند بزرگتر از طول پچ ورودی باشد.
یک سری زمانی با طول ۵۱۲ نقطه زمانی را در نظر بگیرید که برای آموزش مدل TimesFM با طول پچ ورودی ۳۲ و طول پچ خروجی ۱۲۸ استفاده میشود. در طول آموزش، مدل به طور همزمان آموزش میبیند که از ۳۲ نقطه زمانی اول برای پیشبینی ۱۲۸ نقطه زمانی بعدی، از ۶۴ نقطه زمانی اول برای پیشبینی نقاط زمانی ۶۵ تا ۱۹۲، از ۹۶ نقطه زمانی اول برای پیشبینی نقاط زمانی ۹۷ تا ۲۲۴ و به همین ترتیب استفاده کند. در طول استنتاج، فرض کنید مدل یک سری زمانی جدید با طول ۲۵۶ به آن داده شده و وظیفه دارد ۲۵۶ نقطه زمانی آینده را پیشبینی کند. مدل ابتدا پیشبینیهای آینده را برای نقاط زمانی ۲۵۷ تا ۳۸۴ تولید میکند، سپس بر اساس ورودی اولیه به طول ۲۵۶ به علاوه خروجی تولید شده، نقاط زمانی ۳۸۵ تا ۵۱۲ را تولید میکند. از سوی دیگر، اگر در مدل ما طول پچ خروجی برابر با طول پچ ورودی ۳۲ بود، برای همین وظیفه باید هشت مرحله تولید را به جای دو مرحله فوق طی میکردیم. این کار احتمال تجمع خطاهای بیشتری را افزایش میدهد و بنابراین، در عمل مشاهده میکنیم که طول پچ خروجی بلندتر عملکرد بهتری را برای پیشبینی با افق بلند به همراه دارد.
دادههای پیشآموزشی
درست مانند LLMها که با توکنهای بیشتر بهتر میشوند، TimesFM به حجم زیادی از دادههای سری زمانی معتبر برای یادگیری و بهبود نیاز دارد. ما زمان زیادی را صرف ایجاد و ارزیابی مجموعههای داده آموزشی خود کردهایم و نتایج زیر را به دست آوردهایم که بهترین عملکرد را دارند:
دادههای مصنوعی به اصول اولیه کمک میکنند. دادههای سری زمانی مصنوعی و معنیدار را میتوان با استفاده از مدلهای آماری یا شبیهسازیهای فیزیکی تولید کرد. این الگوهای زمانی پایه میتوانند گرامر پیشبینی سریهای زمانی را به مدل آموزش دهند.
دادههای واقعی، طعم دنیای واقعی را اضافه میکنند. ما مجموعههای دادههای سری زمانی عمومی موجود را بررسی میکنیم و به طور انتخابی یک مجموعه بزرگ شامل ۱۰۰ میلیارد نقطه زمانی را گردآوری میکنیم. در میان این مجموعههای داده، گوگل ترندز (Google Trends) و بازدیدهای صفحات ویکیپدیا (Wikipedia Pageviews) وجود دارند که علاقهمندیهای مردم را ردیابی میکنند و به خوبی منعکسکننده روندها و الگوهای موجود در بسیاری دیگر از سریهای زمانی واقعی هستند. این امر به TimesFM کمک میکند تا تصویر بزرگتر را درک کند و در هنگام ارائه زمینههای خاص دامنه که در طول آموزش دیده نشدهاند، بهتر تعمیم یابد.

نتایج ارزیابی بدون نمونه (Zero-shot)
ما TimesFM را به صورت بدون نمونه (zero-shot) بر روی دادههایی که در طول آموزش دیده نشدهاند، با استفاده از معیارهای محبوب سری زمانی ارزیابی میکنیم. مشاهده میکنیم که TimesFM بهتر از اکثر روشهای آماری مانند ARIMA و ETS عمل میکند و میتواند با مدلهای DL قدرتمندی مانند DeepAR و PatchTST که به طور صریح بر روی سریهای زمانی هدف آموزش دیدهاند، برابری کرده یا حتی بهتر عمل کند.
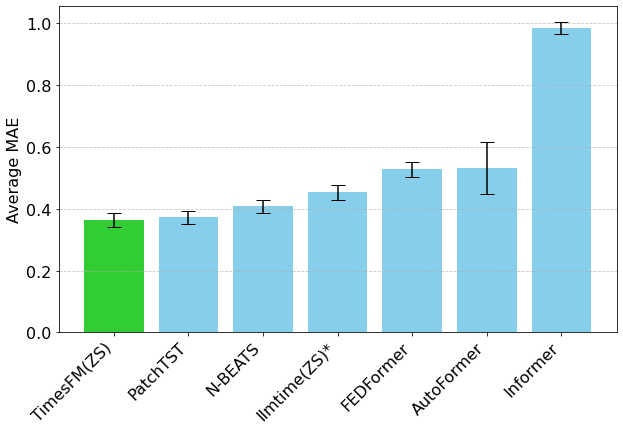
ما از آرشیو پیشبینی موناش (Monash Forecasting Archive) برای ارزیابی عملکرد خارج از جعبه (out-of-the-box) TimesFM استفاده کردیم. این آرشیو شامل دهها هزار سری زمانی از دامنههای مختلف مانند ترافیک، آب و هوا و پیشبینی تقاضا با فرکانسهای مختلف از چند دقیقه تا دادههای سالانه است. مطابق با ادبیات موجود، ما میانگین خطای مطلق (Mean Absolute Error - MAE) را که به طور مناسبی مقیاسبندی شده است تا بتوان آن را در میان مجموعههای داده میانگین گرفت، بررسی میکنیم. مشاهده میکنیم که TimesFM (ZS) بدون نمونه بهتر از اکثر رویکردهای نظارت شده، از جمله مدلهای یادگیری عمیق اخیر است. ما همچنین TimesFM را با GPT-3.5 برای پیشبینی با استفاده از یک تکنیک پرامپتنویسی خاص که توسط llmtime(ZS) پیشنهاد شده، مقایسه میکنیم. نشان میدهیم که TimesFM با وجود اینکه از نظر اندازه چندین مرتبه کوچکتر است، بهتر از llmtime(ZS) عمل میکند.
اکثر مجموعههای داده موناش دارای افق کوتاه یا متوسط هستند، یعنی طول پیشبینی خیلی زیاد نیست. ما TimesFM را بر روی معیارهای محبوب برای پیشبینی با افق بلند در برابر یک خط پایه پیشرفته اخیر PatchTST (و سایر خطوط پایه پیشبینی با افق بلند) نیز آزمایش میکنیم. در شکل بعدی، MAE را بر روی مجموعههای داده ETT برای وظیفه پیشبینی ۹۶ و ۱۹۲ نقطه زمانی در آینده رسم میکنیم. این معیار بر روی آخرین پنجره آزمون هر مجموعه داده (همانطور که در مقاله llmtime انجام شده) محاسبه شده است. مشاهده میکنیم که TimesFM نه تنها از عملکرد llmtime(ZS) پیشی میگیرد، بلکه با مدل نظارتشده PatchTST که به طور صریح بر روی مجموعههای داده مربوطه آموزش دیده است، برابری میکند.
نتیجهگیری
ما یک مدل بنیادین فقط-رمزگشا را برای پیشبینی سریهای زمانی با استفاده از یک مجموعه پیشآموزشی بزرگ شامل ۱۰۰ میلیارد نقطه داده واقعی، که اکثریت آن دادههای سری زمانی علاقه جستجو برگرفته از گوگل ترندز و بازدید صفحات ویکیپدیا بود، آموزش دادیم. نشان میدهیم که حتی یک مدل پیشآموزشی نسبتاً کوچک با ۲۰۰ میلیون پارامتر که از معماری TimesFM ما استفاده میکند، عملکرد چشمگیری در یادگیری بدون نمونه (zero-shot) بر روی معیارهای عمومی مختلف از دامنهها و دقتهای متفاوت از خود نشان میدهد.
تشکر و قدردانی
این کار نتیجه همکاری چندین نفر در گوگل ریسرچ و گوگل کلود است، از جمله (به ترتیب حروف الفبا): آبیمانیو داس، ویائو کونگ، اندرو لیچ، مایک لارنس، الکس مارتین، راجت سن، یانگ یانگ، سکندر حناچی، ایوان کوزنتسف و ییچن ژو.