امروز، ما مدلهای بونسای ۱ بیتی را معرفی میکنیم که هوش پیشرفته را به دستگاههایی میآورند که مردم واقعاً در آنها زندگی و کار میکنند.
در دههی گذشته، هوش مصنوعی مسیر مشخصی را طی کرده است: برای ساخت مدلهای هوشمندتر، آنها را بزرگتر میکنید. پارامترهای بیشتر، پردازندههای گرافیکی (GPU) بیشتر، توان بیشتر، حافظه بیشتر و هزینه بیشتر. این رویکرد موفقیتآمیز بود و مدلهایی را به ما داد که میتوانند در زمینههای وسیع استدلال کنند، مسائل دشوار را حل کنند و نرمافزار، تحقیق و کارهای خلاقانه را با کیفیتی چشمگیر تولید کنند.
اما این رویکرد همچنین یک محدودیت ساختاری عمیق برای آینده هوش مصنوعی ایجاد کرد: توانمندترین هوش در خوشههای عظیم و زیرساختهای تخصصی محبوس شد. با این حال، برخی از مهمترین کاربردهای هوش مصنوعی به مراکز داده محدود نمیشوند. آنها روی گوشیها، لپتاپها، وسایل نقلیه، رباتها، محیطهای امن سازمانی و دستگاههای لبه اتفاق میافتند.
استقرار هوش مصنوعی دیگر با جایی که به آن نیاز است، همخوانی ندارد. امروز، این وضعیت تغییر میکند.
مسیر جدید رو به جلو: تمرکز هوش
امروز، ما پریزمامال را معرفی میکنیم، یک آزمایشگاه هوش مصنوعی که متمرکزترین شکل هوش را میسازد. ما که از تحقیقات پیشگامانه توسعهیافته در کلتک (Caltech) بیرون آمدهایم، با این باور اصلی هدایت میشویم که جهشهای بزرگ بعدی در هوش مصنوعی نه تنها با افزایش صرف تعداد پارامترها، بلکه با بهبودهای مرتبه بزرگی در چگالی هوش (intelligence density) به دست خواهند آمد.
تمرکز هوش به معنای افزایش هوش مفید است که یک مدل به ازای هر واحد اندازه، توان و ردپای استقرار ارائه میدهد. این امر به عوامل مختلفی بستگی دارد: سختافزاری که مدل روی آن اجرا میشود، جزئیات بار کاری، اما مهمتر از همه، اندازه مدل. به همین دلیل، در پریزمامال، ما بر بهینهسازی چگالی هوش، یعنی میزان هوشی که یک مدل میتواند در هر واحد اندازه (بر حسب گیگابایت) ارائه دهد، تمرکز کردهایم. این یک معیار عملی است که تعیین میکند آیا هوش مصنوعی پیشرفته در زیرساختهای گرانقیمت قفل میماند یا در هر کجا که نیاز باشد در دسترس قرار میگیرد.
کلاس جدید مدلهای ما برای دستیابی به دقت آماده تولید در دستگاههای لبه طراحی شدهاند و فناوری اصلی ما هوش تغییر دهنده صنعت را در فضای ابری فعال خواهد کرد.
یک مدل ۱ بیتی واقعی
بونسای ۱ بیتی ۸ میلیارد پارامتری، طراحی اختصاصی مدل ۱ بیتی را در کل شبکه پیادهسازی میکند: لایههای جاسازی (embeddings)، لایههای توجه (attention layers)، لایههای MLP و سر LM همگی ۱ بیتی هستند. هیچ راه فرار با دقت بالاتر وجود ندارد. این یک مدل ۱ بیتی واقعی، از ابتدا تا انتها، با ۸.۲ میلیارد پارامتر است.
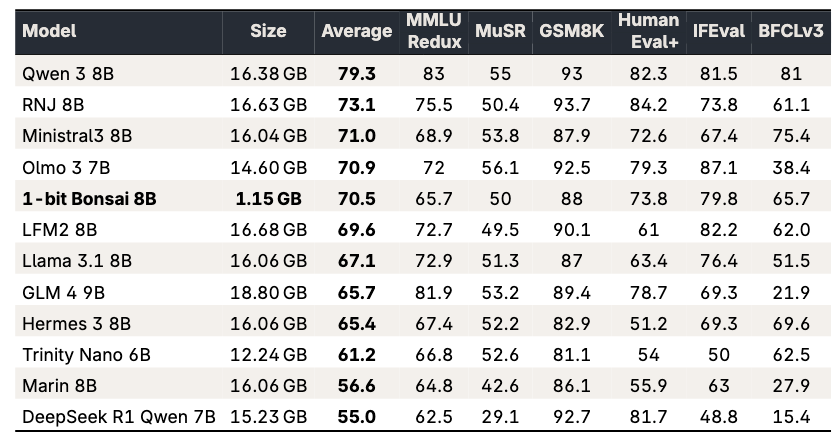
علیرغم اینکه ۱۴ برابر کوچکتر از مدلهای ۸ میلیارد پارامتری (۱۶ بیتی) با دقت کامل در کلاس پارامتری خود است، عملکرد رقابتی در بنچمارکهای استاندارد ارائه میدهد، در حالی که با کارایی رادیکال بالاتری عمل میکند.
این موضوع مهم است زیرا فشردهسازی مدل در طول تاریخ با بدهبستانهای دردناکی همراه بوده است. مدلهای با بیت پایین اغلب قابلیتهای زیادی را در پیروی از دستورالعملها، استدلال چند مرحلهای و استفاده قابل اعتماد از ابزارها از دست میدهند تا بتوانند به عنوان پایه و اساس محصولات جدی عمل کنند. در عمل، آنها برای استقرار عملی کافی نیستند.
بونسای این وضعیت را تغییر میدهد. این مدل نشان میدهد که مدلهای ۱ بیتی نیازی به سازشهای محدود ندارند. آنها میتوانند سیستمهای توانا و آماده تولید باشند.
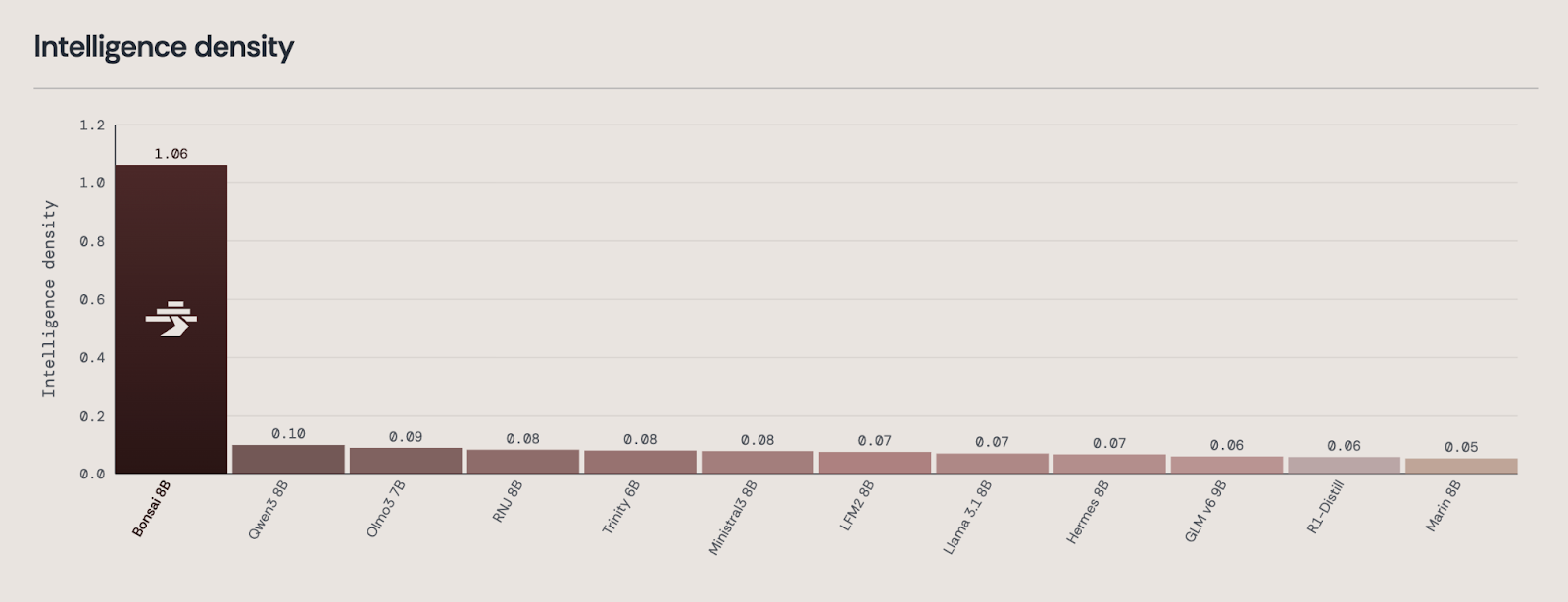
چگالی هوش
در مجموعه گستردهای از بنچمارکها، بونسای ۱ بیتی ۸ میلیارد پارامتری، بهبود سطح قابلیت به ازای اندازه مدل را نه تنها یک گام کوچک رو به جلو، بلکه یک جهش بزرگ ارائه میدهد. برای ثبت دقیق این موضوع، ما چگالی هوش را اندازهگیری میکنیم.
ما چگالی هوش را به عنوان منفی لگاریتم نرخ خطای متوسط مدل (در همان مجموعه بنچمارک) تقسیم بر اندازه مدل تعریف میکنیم. اگرچه این معیار دستاوردهای کوچکتری را برای بونسای نسبت به نمرات خام متوسط بنچمارک (مثلاً ۱۰.۶ برابر در مقابل ۱۲.۷ برابر بیشتر از Qwen3 8B) نشان میدهد، اما معتقدیم که دیدگاه واقعیتری از هوش ارائه میدهد. برخلاف میانگینهای ساده بنچمارک، این معیار به بهبودهای نزدیک به دقت بالا، جایی که معمولاً دستیابی به دستاوردهای بیشتر دشوارتر است، ارزش بیشتری میدهد تا بهبودهای هماندازه در سطوح عملکرد پایینتر.
با این معیار، بونسای ۱ بیتی ۸ میلیارد پارامتری به امتیاز چگالی هوش ۱.۰۶ گیگابایت دست مییابد. در میان مدلهای نزدیک از نظر تعداد پارامتر، نزدیکترین مدل، Qwen3 8B، امتیاز ۰.۱۰ گیگابایت را کسب میکند. بونسای نه تنها در این معیار پیشتاز است؛ بلکه در یک قلمرو متفاوت قرار دارد.
در میانگینهای خام بنچمارک، بونسای ۱ بیتی ۸ میلیارد پارامتری با مدلهای پیشرو کلاس ۸ میلیارد پارامتری رقابت میکند، اما این کار را با حجم حافظه تنها ۱.۱۵ گیگابایت انجام میدهد که تقریباً ۱۲ تا ۱۴ برابر کوچکتر از همتایان خود است. این هسته چگالی هوش است: نه تنها قابلیت قوی، بلکه قابلیت قوی که به شکلی به مراتب قابل استقرارتر ارائه میشود.
این فقط آغاز این دسته است. نسلهای آتی ما مرزهای چگالی هوش را جابجا خواهند کرد.
چه چیزی ممکن میشود وقتی هوش اینقدر متمرکز باشد
هنگامی که مدلهای پیشرفته به اندازه کافی کوچک، سریع و کارآمد میشوند تا به صورت محلی اجرا شوند، فضای طراحی برای هوش مصنوعی بلافاصله تغییر میکند.
محصولات پاسخگوتر میشوند زیرا هوش میتواند روی دستگاه با تأخیر بسیار کمتر اجرا شود. سیستمها خصوصیتر میشوند زیرا دادههای حساس دیگر نیازی به ترک دستگاه یا عبور از مرزهای سازمانی ندارند. برنامهها قابل اعتمادتر میشوند زیرا کمتر به دسترسی مداوم به ابر وابسته هستند. و هوش مصنوعی در محیطهایی که استقرار سمت سرور قبلاً بسیار گران بود، از نظر اقتصادی امکانپذیر میشود.
دستههای کاملاً جدیدی نیز شروع به باز شدن میکنند: عاملهای پایدار روی دستگاه، رباتیک بلادرنگ، دستیاران امن سازمانی، هوش آفلاین و محصولات بومی هوش مصنوعی که برای محیطهایی ساخته شدهاند که محدودیتهای پهنای باند، توان یا انطباق، مدلهای پیشرفته را قبلاً غیرعملی میکردند.
به همین دلیل است که ما هوش متمرکز را چیزی بیش از یک بهبود کارایی میدانیم. این هوش سطح هوش را گسترش میدهد و در نتیجه محصولات هوش مصنوعی میتوانند چه باشند. آینده هوش مصنوعی تنها به ابر محدود نخواهد شد. بلکه شامل ابر، دستگاههای لبه و هر آنچه در این بین است، خواهد بود.
دمو ۱: مدل بونسای ۱ بیتی ۸ میلیارد پارامتری که روی یک آیفون ۱۷ پرو با تقریباً ۴۰ توکن بر ثانیه اجرا میشود. یک مدل استاندارد ۱۶ بیتی ۸ میلیارد پارامتری نمیتواند روی هیچ آیفونی جا شود. برای مقایسه، ما همچنین یک مدل ۱۶ بیتی ۱ میلیارد پارامتری را نشان میدهیم که با ۲۳ توکن بر ثانیه روی همان پرامپت MATH-500 اجرا میشود و شکاف قابل توجهی را در دقت و سرعت برجسته میکند.
اندازه و سرعت
بونسای ۱ بیتی ۸ میلیارد پارامتری تنها ۱.۱۵ گیگابایت است. با این اندازه، به اندازه کافی کوچک است که روی یک آیفون ۱۷ پرو جا شود. در مقایسه با مدلهایی با عملکرد مشابه، این امر تقریباً ۱۴ برابر کاهش در اندازه مدل را نشان میدهد. این کاهش صرفاً ظاهری نیست. این امر تغییر میدهد که چه سختافزاری میتواند هوش جدی را میزبانی کند.
در بین دستگاهها، بونسای همچنین دستاوردهای عمدهای در توان عملیاتی (throughput) ارائه میدهد. روی یک مک M4 پرو، با سرعت ۱۳۱ توکن بر ثانیه اجرا میشود. روی یک RTX 4090، به ۳۶۸ توکن بر ثانیه میرسد. روی یک آیفون ۱۷ پرو مکس، تقریباً با سرعت ۴۴ توکن بر ثانیه اجرا میشود.
دمو ۲: مدل بونسای ۱ بیتی ۸ میلیارد پارامتری که روی یک مک M4 پرو در کنار یک مدل استاندارد ۱۶ بیتی ۸ میلیارد پارامتری اجرا میشود.
از دموی بالا روی M4 پرو، تفاوت بلافاصله آشکار است: بونسای کسری از حافظه را استفاده میکند در حالی که سرعت تولید به مراتب بالاتری را ارائه میدهد. از آنجا که مدل میتواند به صورت محلی اجرا شود، این دستاوردها بدون تأخیر غیرضروری شبکه حاصل میشوند. نتیجه تجربهای است که اساساً با هوش مصنوعی وابسته به ابر متفاوت است: سریعتر، مستقیمتر و در دسترستر.
دمو ۳: مدل بونسای ۱ بیتی ۸ میلیارد پارامتری که روی یک مک M4 پرو در کنار یک مدل استاندارد ۱۶ بیتی ۸ میلیارد پارامتری اجرا میشود و یک وظیفه عاملمحور با افق طولانی را به صورت محلی شبیهسازی میکند.
مزیت در بارهای کاری عاملمحور با افق طولانی حتی واضحتر میشود. در دموی بالا، ما ۵۰ وظیفه خلاصه و تخصیص تیکت را شبیهسازی میکنیم. مدل بونسای ۱ بیتی ۸ میلیارد پارامتری هر ۵۰ تیکت را تکمیل میکند، در حالی که مدل استاندارد ۱۶ بیتی ۸ میلیارد پارامتری تنها ۶ تیکت را در همان بازه زمانی انجام میدهد. برای عاملهایی که باید استدلال را در چندین مرحله حفظ کنند، توان عملیاتی بالاتر و استفاده کمتر از حافظه نه تنها سیستم را سریعتر میکند، بلکه میزان کاری را که عامل میتواند به طور واقعبینانه انجام دهد، گسترش میدهد.
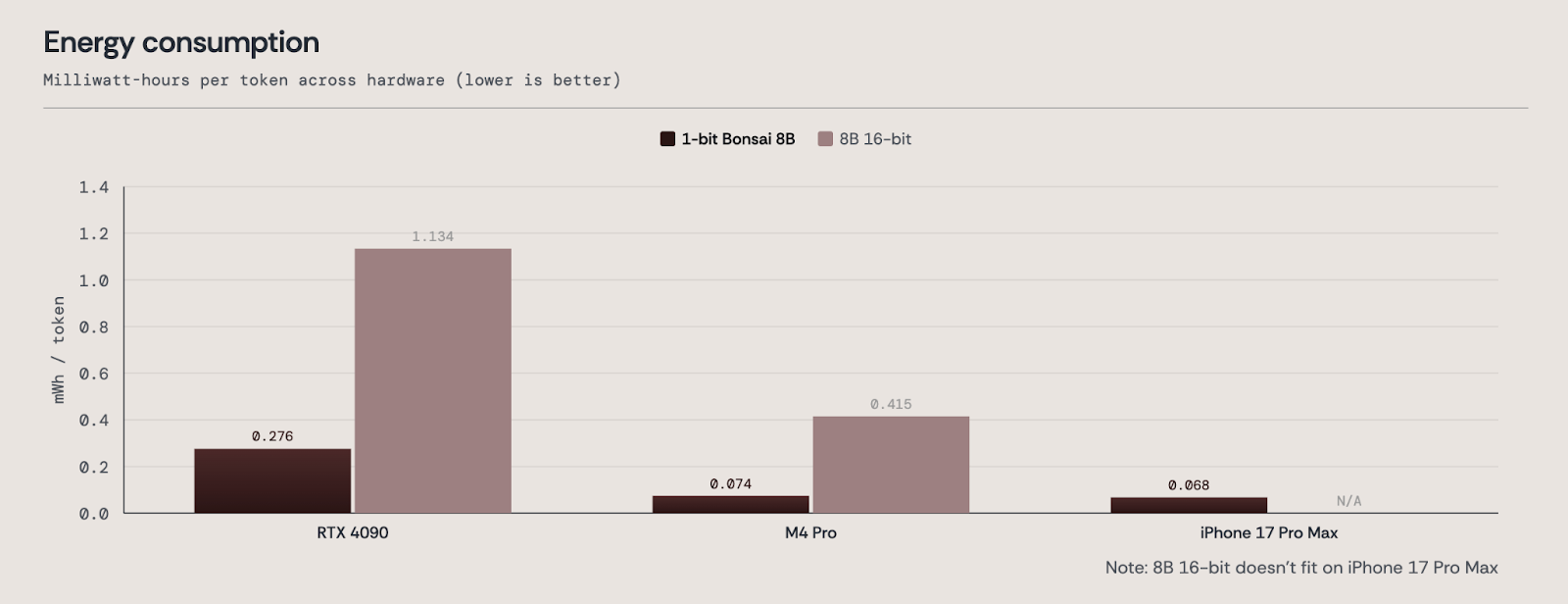
مصرف انرژی
هوش مصنوعی تنها در صورتی به زیرساختهای اساسی تبدیل خواهد شد که به طور چشمگیری کارآمدتر شود.
بونسای ۱ بیتی ۸ میلیارد پارامتری انرژی بسیار کمتری نسبت به همتایان ۱۶ بیتی با دقت کامل خود مصرف میکند و تقریباً ۴ تا ۵ برابر کارایی انرژی بهتری ارائه میدهد. روی M4 پرو، به ۰.۰۷۴ میلیوات ساعت بر توکن و روی آیفون ۱۷ پرو مکس، تنها به ۰.۰۶۸ میلیوات ساعت بر توکن نیاز دارد.
این موضوع مهم است زیرا کارایی انرژی فقط یک معیار سیستمی نیست. اقتصاد واقعی هوش مصنوعی را شکل میدهد.
سختافزار ۱ بیتی؟
افزایش سرعت و صرفهجویی در انرژی بالا روی سختافزارهای تجاری استاندارد امروزی به دست آمدهاند، که برای محاسبات با دقت کامل طراحی و بهینه شدهاند.
نکته مهم این است که این دستاوردها عمدتاً از کاهش حجم حافظه مدلهای ۱ بیتی ناشی میشوند، نه هنوز از بهرهبرداری کامل از ساختار ۱ بیتی وزنها در طول استنتاج. به عبارت دیگر، بونسای در حال حاضر مزایای قابل توجهی را روی سختافزاری ارائه میدهد که برای این کلاس از مدلها ساخته نشده بود.
اما مدلهای ۱ بیتی همچنین راه را برای یک فرصت عمیقتر سیستمی باز میکنند. در لایههای خطی مانند MLPs، وزنهای ۱ بیتی امکان انجام استنتاج را با ضرب کم یا بدون ضرب فراهم میکنند و بخش زیادی از محاسبات را با جمعهای ساده جایگزین میکنند. بنابراین، سختافزاری که به طور خاص برای استنتاج ۱ بیتی طراحی شده باشد، میتواند عملکرد و کارایی انرژی را بسیار بیشتر، احتمالاً تا یک مرتبه بزرگی دیگر، افزایش دهد.
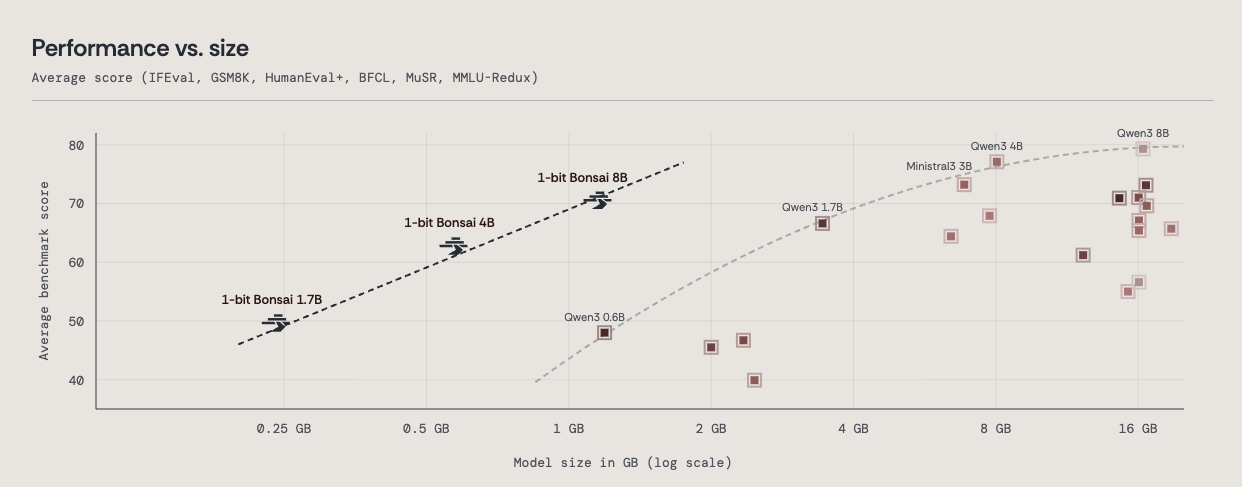
بونسای ۴ میلیارد پارامتری و بونسای ۱.۷ میلیارد پارامتری
برای نمایش بیشتر قدرت رویکرد ما، دو مدل کوچکتر دیگر نیز منتشر میکنیم: بونسای ۱ بیتی ۴ میلیارد پارامتری و بونسای ۱ بیتی ۱.۷ میلیارد پارامتری. هر دو توان عملیاتی و کارایی انرژی قوی را ارائه میدهند در حالی که دقت پیشرو را برای اندازه خود حفظ میکنند.
برای بررسی بیشتر بدهبستان بین اندازه یک مدل و امتیاز متوسط بنچمارک آن، ۲۰ مدل دستورالعمل (instruct) پیشرو را در اندازههایی از ۱.۲ گیگابایت (Qwen3 0.6B) تا ۱۶.۴ گیگابایت (Qwen3 8B) در نظر گرفتیم. نمودار پراکندگی حاصل، مرز پارتوی هوش در مقابل اندازه را نشان میدهد که توسط مدلهای Qwen3 0.6B، 1.7B، 4B و 8B و همچنین Ministral3 3B تعریف شده است.
بونسای ۱ بیتی ۸ میلیارد پارامتری، همراه با مدلهای خواهر کوچکتر خود، یعنی بونسای ۱ بیتی ۱.۷ میلیارد پارامتری و ۴ میلیارد پارامتری، مرز پارتوی (هوش در مقابل اندازه مدل) را به شدت به سمت چپ جابجا میکند. این اکنون مرز جدید است.
مسیر از پیشرفت تا فراگیری
نوآوری انسان اغلب یک مسیر مشابه را دنبال میکند: ابتدا ثابت میکنیم چیزی ممکن است، سپس آن را دموکراتیک میکنیم و آن را کوچکتر، ارزانتر و برای همه قابل دسترس میسازیم. رایانههای اولیه کل اتاقها را پر میکردند و دوربینها زمانی به تنظیمات دقیق و زمانهای نوردهی طولانی نیاز داشتند. امروز، آنها در جیب ما زندگی میکنند.
این انتقال در هوش مصنوعی قبلاً آغاز شده است. طی پنج سال آینده، مدلها همچنان توانمندتر خواهند شد، اما برخی از مهمترین پیشرفتها از قابل حمل، کارآمد و قابل استقرار کردن هوش به اندازهای که در هر کجا که نیاز باشد زندگی کند، حاصل خواهد شد.
این آیندهای است که پریزمامال در حال ساخت آن است.
پوشش پلتفرم
ما مدلهای بونسای ۱ بیتی را برای کار روی طیف وسیعی از دستگاهها ساختیم.
بونسای ۱ بیتی ۸ میلیارد پارامتری به صورت بومی روی دستگاههای اپل (مک، آیفون، آیپد) از طریق MLX، و روی پردازندههای گرافیکی انویدیا (NVIDIA GPU) از طریق llama.cpp CUDA اجرا میشود. وزنهای مدل امروز تحت مجوز Apache 2.0 در دسترس هستند.
جزئیات فنی کامل آموزش، ارزیابی و فرآیندهای بنچمارکینگ ما در وایتپیپر ما موجود است.