



همکاری جدید بین دانشگاه کالیفرنیا مرسد و ادوبی پیشرفتی در زمینه تکمیل تصاویر انسان (وظیفه بسیار مورد مطالعه 'برداشتن مانع' از بخشهای پوشیده یا پنهان تصاویر افراد برای اهدافی مانند پوشیدن مجازی لباس، انیمیشن و ویرایش عکس) ارائه میدهد.
رویکرد جدید، تحت عنوان CompleteMe: Reference-based Human Image Completion، از تصاویر ورودی تکمیلی برای 'پیشنهاد' محتوایی که باید جایگزین بخش پنهان یا گمشده تصویر انسان شود (از این رو کاربرد آن در چارچوبهای پوشیدن مجازی لباس) استفاده میکند:
سیستم جدید از یک معماری دوگانه U-Net و یک بلوک Region-Focused Attention (RFA) استفاده میکند که منابع را به منطقه مربوطه در نمونه ترمیم تصویر هدایت میکند.
محققان همچنین یک سیستم معیار جدید و چالشبرانگیز را ارائه میدهند که برای ارزیابی وظایف تکمیل مبتنی بر مرجع طراحی شده است (زیرا CompleteMe بخشی از یک رشته تحقیقاتی موجود و جاری در بینایی کامپیوتر است، اگرچه تا کنون هیچ طرح معیاری نداشته است).
در آزمایشها و در یک مطالعه کاربری مقیاسپذیر، روش جدید در اکثر معیارها و به طور کلی پیشتاز بود. در موارد خاص، روشهای رقیب به کلی توسط رویکرد مبتنی بر مرجع شکست خوردند:
مقاله بیان میکند:
«آزمایشهای گسترده روی معیار ما نشان میدهد که CompleteMe از روشهای پیشرفته، هم مبتنی بر مرجع و هم غیرمبتنی بر مرجع، از نظر معیارهای کمی، نتایج کیفی و مطالعات کاربری پیشی میگیرد.
«به ویژه در سناریوهای چالشبرانگیز شامل ژستهای پیچیده، الگوهای لباس پیچیده و لوازم جانبی متمایز، مدل ما به طور مداوم به وفاداری بصری و همبستگی معنایی برتر دست مییابد.»
متأسفانه، حضور پروژه در گیتهاب حاوی هیچ کدی نیست و وعده هیچ کدی را نیز نمیدهد، و این ابتکار، که یک صفحه پروژه متوسط نیز دارد، به نظر میرسد به عنوان یک معماری اختصاصی طراحی شده است.

روش
چارچوب CompleteMe بر پایه یک Reference U-Net استوار است که مسئول ادغام مواد کمکی در فرآیند است، و یک cohesive U-Net که طیف گستردهتری از فرآیندها را برای دستیابی به نتیجه نهایی در خود جای میدهد، همانطور که در طرح مفهومی زیر نشان داده شده است:
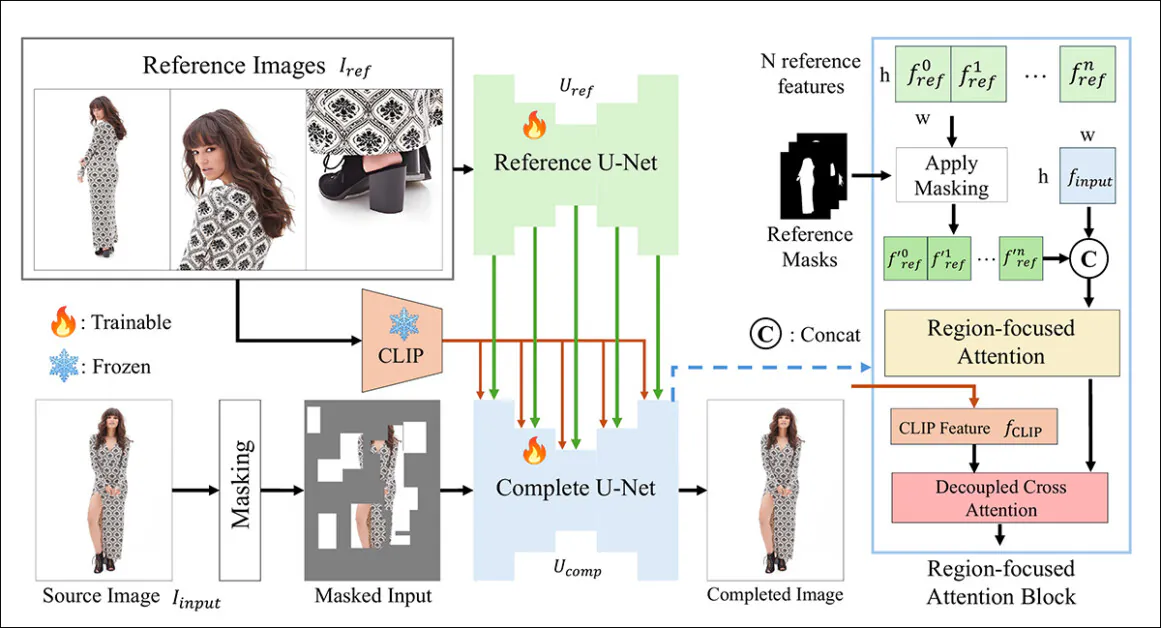
سیستم ابتدا تصویر ورودی پوشانده شده را در یک نمایش نهفته رمزگذاری میکند. در عین حال، Reference U-Net چندین تصویر مرجع - هر کدام مناطق مختلف بدن را نشان میدهند - را پردازش میکند تا ویژگیهای فضایی دقیق را استخراج کند.
این ویژگیها از طریق یک بلوک Region-focused Attention که در U-Net 'کامل' تعبیه شده است، عبور میکنند، جایی که با استفاده از ماسکهای منطقه مربوطه به صورت انتخابی پوشانده میشوند، اطمینان حاصل میشود که مدل فقط به مناطق مربوطه در تصاویر مرجع توجه کند.
ویژگیهای پوشانده شده سپس با ویژگیهای معنایی جهانی مشتق شده از CLIP از طریق cross-attention تفکیک شده ادغام میشوند، که به مدل امکان میدهد محتوای گمشده را با جزئیات دقیق و همبستگی معنایی بازسازی کند.
برای افزایش واقعگرایی و استحکام، فرآیند پوشاندن ورودی ترکیب تصادفی پوششهای مبتنی بر شبکه با ماسکهای شکل بدن انسان را در بر میگیرد که هر کدام با احتمال مساوی اعمال میشوند و پیچیدگی مناطق گمشدهای که مدل باید تکمیل کند را افزایش میدهند.

فقط برای مرجع
روشهای قبلی برای پر کردن تصویر مبتنی بر مرجع معمولاً به رمزگذارهای سطح معنایی متکی بودند. پروژههای از این دست شامل خود CLIP و DINOv2 هستند که هر دو ویژگیهای جهانی را از تصاویر مرجع استخراج میکنند، اما اغلب جزئیات فضایی دقیقی را که برای حفظ دقیق هویت لازم است از دست میدهند.
CompleteMe این جنبه را از طریق یک Reference U-Net تخصصی که از Stable Diffusion 1.5 اولیه سازی شده است، اما بدون مرحله نویز انتشار* عمل میکند، حل میکند.
هر تصویر مرجع که مناطق مختلف بدن را پوشش میدهد، از طریق این U-Net به ویژگیهای نهفته دقیق رمزگذاری میشود. ویژگیهای معنایی جهانی نیز به طور جداگانه با استفاده از CLIP استخراج میشوند و هر دو مجموعه ویژگی برای استفاده کارآمد در طول ادغام مبتنی بر توجه ذخیره میشوند. بنابراین، سیستم میتواند چندین ورودی مرجع را با انعطافپذیری در خود جای دهد، در حالی که اطلاعات ظاهری دقیق را حفظ میکند.

هماهنگی
U-Net منسجم مراحل نهایی فرآیند تکمیل را مدیریت میکند. این مدل که از نسخه پر کردن تصویر Stable Diffusion 1.5 اقتباس شده است، تصویر منبع پوشانده شده را در قالب نهفته به همراه ویژگیهای فضایی دقیق از تصاویر مرجع و ویژگیهای معنایی جهانی استخراج شده توسط رمزگذار CLIP به عنوان ورودی دریافت میکند.
این ورودیهای مختلف از طریق بلوک RFA که نقش مهمی در هدایت تمرکز مدل به سمت مرتبطترین مناطق مواد مرجع دارد، به هم میرسند.
قبل از ورود به مکانیسم توجه، ویژگیهای مرجع به صراحت پوشانده میشوند تا مناطق نامرتبط حذف شوند و سپس با نمایش نهفته تصویر منبع الحاق میشوند، که اطمینان حاصل میکند توجه با دقت هرچه بیشتر هدایت میشود.
برای افزایش این ادغام، CompleteMe یک مکانیسم cross-attention تفکیک شده را در بر میگیرد که از چارچوب IP-Adapter اقتباس شده است:
این امکان را به مدل میدهد تا ویژگیهای بصری با جزئیات فضایی و زمینه معنایی گستردهتر را از طریق جریانهای توجه جداگانه پردازش کند که بعداً ترکیب میشوند و منجر به بازسازی منسجمی میشوند که به گفته نویسندگان، هم هویت و هم جزئیات دقیق را حفظ میکند.


معیارسازی
در غیاب یک مجموعه داده مناسب برای تکمیل انسان مبتنی بر مرجع، محققان مجموعه داده خود را پیشنهاد کردهاند. معیار (بینام) با انتخاب جفت تصاویر منتخب از مجموعه داده WPose که برای پروژه UniHuman ادوبی ریسرچ در سال ۲۰۲۳ طراحی شده بود، ساخته شد.
محققان ماسکهای منبع را به صورت دستی رسم کردند تا مناطق پر کردن تصویر را مشخص کنند و در نهایت ۴۱۷ گروه تصویری سهبخشی شامل یک تصویر منبع، ماسک و تصویر مرجع به دست آوردند.
نویسندگان از مدل زبان بزرگ (LLM) LLaVA برای تولید متن توصیف کننده تصاویر منبع استفاده کردند.
معیارهای استفاده شده گستردهتر از حد معمول بودند؛ علاوه بر نسبت سیگنال به نویز پیک (PSNR)، شاخص شباهت ساختاری (SSIM) و شباهت بصری بخش تصویر یادگیری شده (LPIPS، در این مورد برای ارزیابی مناطق پوشانده شده)، محققان از DINO برای امتیازات شباهت استفاده کردند؛ DreamSim برای ارزیابی نتایج تولید؛ و CLIP.


دادهها و آزمایشها
برای آزمایش کار، نویسندگان از هر دو مدل پیش فرض Stable Diffusion V1.5 و مدل پر کردن تصویر 1.5 استفاده کردند. رمزگذار تصویر سیستم از مدل Vision CLIP به همراه لایههای پروجکشن - شبکههای عصبی کوچک که خروجیهای CLIP را برای مطابقت با ابعاد ویژگی داخلی استفاده شده توسط مدل تغییر شکل یا تراز میکنند - استفاده کرد.
آموزش به مدت ۳۰,۰۰۰ تکرار بر روی هشت GPU NVIDIA A100† انجام شد، تحت نظارت خطای میانگین مربعات (MSE)، با اندازه دسته ۶۴ و نرخ یادگیری ۲×۱۰-۵. عناصر مختلفی به صورت تصادفی در طول آموزش حذف شدند تا سیستم بیشبرازش روی دادهها را نداشته باشد.
مجموعه داده از مجموعه داده Parts to Whole که خود بر اساس مجموعه داده DeepFashion-MultiModal است، اصلاح شد.
نویسندگان بیان میکنند:
«برای برآورده کردن نیازهای ما، جفتهای آموزشی را با استفاده از تصاویر پوشیده شده با چندین تصویر مرجع که جنبههای مختلف ظاهر انسان را به همراه برچسبهای متنی کوتاه آنها ثبت میکنند، [بازسازی کردیم].
«هر نمونه در دادههای آموزشی ما شامل شش نوع ظاهر است: لباس قسمت بالاتنه، لباس قسمت پایین تنه، لباس تمام بدن، مو یا کلاه، صورت و کفش. برای استراتژی پوشاندن، ما ۵۰٪ پوشاندن تصادفی مبتنی بر شبکه بین ۱ تا ۳۰ بار اعمال میکنیم، در حالی که برای ۵۰٪ دیگر، از ماسک شکل بدن انسان برای افزایش پیچیدگی پوشاندن استفاده میکنیم.
«پس از خط لوله ساخت و ساز، ما ۴۰,۰۰۰ جفت تصویر برای آموزش به دست آوردیم.»
روشهای پیشین غیرمرجع رقیب که آزمایش شدند عبارتند از تکمیل تصویر انسان با پوشش بزرگ (LOHC) و مدل پر کردن تصویر plug-and-play BrushNet؛ مدلهای مبتنی بر مرجع که آزمایش شدند عبارتند از Paint-by-Example؛ AnyDoor؛ LeftRefill؛ و MimicBrush.
نویسندگان با مقایسه کمی بر روی معیارهای قبلاً ذکر شده شروع کردند:
جدول نشان میدهد CompleteMe در اکثر معیارها بهتر عمل میکند، اگرچه نه در همه آنها.
برای ارائه مقایسه عادلانهتر از عملکرد ذهنی، نویسندگان سپس یک مطالعه انسانی انجام دادند و از ۳۰ داوطلب در آمازون Mechanical Turk خواستند تا کیفیت بصری تصاویر تولید شده توسط CompleteMe را با تصاویر تولید شده توسط شش روش قابل مقایسه مقایسه کنند.
به شرکتکنندگان جفت تصاویری نشان داده شد، یکی توسط CompleteMe و دیگری توسط یک رقیب تولید شده بود، کنار هم، و از آنها خواسته شد انتخاب کنند کدام یک کیفیت بصری، همبستگی معنایی و حفظ هویت بهتری دارد. در مواردی که تفاوت قابل تشخیصی وجود نداشت، شرکتکنندگان میتوانستند 'مساوی' را انتخاب کنند.
CompleteMe در همه دستهها، به ویژه در حفظ هویت، به شدت مورد حمایت قرار گرفت.
مقاله نتیجه میگیرد:
«ما CompleteMe را ارائه دادیم، یک چارچوب جدید برای تکمیل تصویر انسان مبتنی بر مرجع. رویکرد ما از معماری دوگانه U-Net با یک مکانیسم توجه متمرکز بر منطقه و یک ماژول cross-attention تفکیک شده برای ادغام مؤثر اطلاعات فضایی و معنایی از تصاویر مرجع استفاده میکند که منجر به وفاداری بصری و حفظ هویت برتر میشود.
«علاوه بر این، ما یک معیار جدید برای ارزیابی تکمیل تصویر انسان مبتنی بر مرجع معرفی کردهایم که تحقیقات آینده در این زمینه را تسهیل خواهد کرد. آزمایشهای جامع و یک مطالعه کاربری در مقیاس بزرگ برتری CompleteMe را نسبت به روشهای پیشرفته موجود نشان میدهد.»
† در این مقاله، هرجا NVIDIA A100 ذکر شده است، به نسخه ۸۰ گیگابایتی اشاره دارد.
اولین بار در ۲۹ آوریل ۲۰۲۵ منتشر شد.