
مطلب اصلی
- تبدیل یک پیدیاف اسکن شده به یک صفحه اکسل کاربرپسند.
- اعتبارسنجی دادههای استخراج شده با همپوشانی آنها روی پیدیاف.
- اشکالزدایی مسائل با استفاده از نقاط توقف شرطی.
- کسب بینش در مورد عادات یادگیری خود و دیگران.
MSLQ چیست؟
پرسشنامه راهبردهای انگیزشی یادگیری (MSLQ) یک گنجینه متعلق به سال ۱۹۹۱ است — تلاشی پنج ساله که ۸۱ سوال را در ۱۵ مقیاس برای سنجش انگیزه و عادات شناختی خلاصه میکند.
به عنوان یک علاقهمند به فناوری آموزشی، میخواستم از آن برای درک بهتر خودم و حمایت از همکارانم استفاده کنم. اما تنها چیزی که پیدا کردم، یک پیدیاف اسکن شده دانهدار از ERIC (مرکز اطلاعات منابع آموزشی: https://eric.ed.gov/?id=ED338122) بود که مهر "بهترین کپی موجود" بر روی آن خورده بود.
مرا دنبال کنید
این فرآیند حدود ۱۵ دقیقه طول میکشد.
چند درس به یاد ماندنی را انتخاب کنید، سپس شروع به پاسخ دادن به ۸۱ سوال در صفحه ۳۶ پیدیاف کنید.
از خواندن صفحات قبلی خودداری کنید تا پاسخهای شما بیطرفانه بماند.
در ابتدا شروع به نوشتن پاسخهایی مانند "۱۴۳۳۱ ۳۴۴۵۶" روی کاغذ کردم، اما به سرعت متوجه شدم که این روش مقیاسپذیر نیست.
با کنار گذاشتن عادات قدیمی، به کلود، بهترین مدل هوش مصنوعی رایگان که میشناسم، روی آوردم تا توانایی OCR آن را آزمایش کرده و فرآیند را سادهسازی کنم.



پرامپت استخراج
در MSLQ تعداد ۸۱ سوال وجود دارد. یک صفحه اکسل ایجاد کنید که کاربر بتواند پاسخهای خود را برای ۸۱ سوال با تایپ اعداد پر کند و ۹ مقیاس به طور خودکار محاسبه شوند. هر یک از ۹ مقیاس به مجموعهای از سوالات غیر همپوشان و غیر متوالی مرتبط هستند. من پاسخدهنده زیادی ندارم، بنابراین میخواهم برای هر سوال یک ردیف و ستونها نشاندهنده پاسخدهندگان باشند. همچنین میخواهم یک توضیح خوانا از سوال برای هر ردیف به عنوان چپترین ستون داشته باشم. نتایج ۹ مقیاس برای هر پاسخدهنده باید در یک برگه (تب) جدید در اکسل ظاهر شود.
کد استخراج
این کد پایتون نهایی پس از تغییرات است: MSLQ_excel_template to create excel after OCR on MSLQ.pdf
بسیار چشمگیر است که ۶۰۰ خط کد تقریباً بیعیب و نقص را در یک لحظه تولید کرد!
اگرچه MSLQ دارای ۱۵ مقیاس است، من روی ۹ مقیاس که بازخورد نمونه در پیدیاف داشتند، تمرکز کردم. بازیابی ۶ مقیاس دیگر به سادگی ویرایش selected_scales است.
۱۵ مقیاس، ۸۱ سوال را به صورت متقابلاً انحصاری گروهبندی میکنند.
برای کلود دست بزنید
- تمام ۸۱ سوال را به ترتیب و با شمارهگذاری صحیح استخراج کرد (شروع از ۱، نه از ۰ مانند پایتون). این کار در زمان جستجو برای سوالات و کدنویسی دستی رشتهها صرفهجویی کرد.
- ۸ سوال با کدگذاری معکوس (reverse coded) را پیدا کرد. کدگذاری معکوس به این معنی است که پاسخهای پایینتر، نمرات بالاتری به همراه دارند. پاسخهای سوالات با کدگذاری معکوس از ۸ کسر میشوند تا مقیاس ۱-۷ به ۷-۱ معکوس شود.
- سوالات را در ۹ مقیاس گروهبندی کرد، که ساعتها پیمایش دستی در پیدیاف ۷۵ صفحهای را ذخیره کرد. ما باید پیمایش کنیم زیرا طبق طراحی، پرسشنامهها سوالات را به هم میریزند تا مقیاسهای مرتبط به صورت متوالی ظاهر نشوند.
- تجربه کاربری (UX) خوب — دستورالعملها در بالا سمت چپ ارائه شدهاند تا اکسل خود توضیحی باشد و سرصفحهها رنگی شدهاند.
- تجربه کاربری خوب — یک واسط خط فرمان (CLI) برای مسیر خروجی و تعداد پاسخدهندگان گنجانده شد، که بعداً برای سرعت، آن را به صورت دستی کدگذاری کردم.
- فرمولهای پیچیده اکسل برای AVERAGE، COUNTIF، IF، و ارجاعات در بین برگهها همگی صحیح هستند.
- ساختارهای داده را تنظیم کرد و به طور ضمنی مدلسازی داده را انجام داد.
mslq_questions = [
# Format: [question_number, question_text, scale, is_reversed]
[
1,
"In a class like this, I prefer course material that really challenges me so I can learn new things.",
"Intrinsic Goal Orientation",
False,
],
[
2,
"If I study in appropriate ways, then I will be able to learn the material in this course.",
"Control of Learning Beliefs",
False,
],
##################### TRUNCATED ########################آن را امتحان کنید
کد را اجرا کنید تا اکسل تولید شود یا این الگو را کپی کنید: https://docs.google.com/spreadsheets/d/1B9suxNdatBROsPIz8OrdKYoIla-VDR46
اشکالات جزئی
- یک علامت "=" جا افتاده در فرمولها یک اصلاح آسان بود (
f"IF…بهf"=IF…تغییر یافت). شناسایی آن آسان بود زیرا سلولها فرمول را به عنوان یک رشته شامل میشدند. - کد از
fitz، نسخه قدیمیترpymupdfاستفاده میکرد. جایگزینی تمام مواردfitzباpymupdfبدون مشکل کار کرد. - در ابتدا، اطلاعات مقیاسها و کدگذاری معکوس در تب سوالات ظاهر شد که به طور بالقوه پاسخدهندگان را تحت تأثیر قرار میداد. یک پرامپت بعدی این اطلاعات را به یک تب ابرداده جدید منتقل کرد.
مقیاس و معکوس شده؟ نباید در تب سوالات باشد چون پاسخدهنده را تحت تأثیر قرار میدهد. آنها را در یک تب دیگر نشان دهید.
حالا چه؟
با آماده شدن اکسل، نیاز داشتم مطمئن شوم که استخراج کلود دقیق است. آیا میتوانستم به دادههای استخراج شده از یک پیدیاف تار اعتماد کنم؟
اعتبارسنجی با تصویرسازی
از کلود خواستم محلی را که هر سوال، وضعیت کدگذاری معکوس و ارتباط مقیاسها را در پیدیاف پیدا کرده است، برجسته کند، دقیقاً مانند اعتبارسنجی یک ترجمه با ترجمه مجدد آن به زبان مبدأ.
پرامپت اعتبارسنجی
پیدیاف مبدأ MSLQ.pdf پیوست شده است.
میخواهم ببینم اطلاعات استخراج شده در کد در کجای پیدیاف قرار دارند. کد پایتون بنویسید تا پیدیاف را برجسته کند و یک پیدیاف جدید ایجاد کند.
اطلاعاتی که میخواهم بررسی کنم: ۱. متن سوال ۲. آیا هر سوال با کدگذاری معکوس است ۳. ارتباط بین سوالات و مقیاس.
کد اعتبارسنجی
کد را اینجا ببینید: Read MSLQ.pdf and add highlights and summary page to create MSLQ_highlighted.pdf.
این کد MSLQ_highlighted.pdf را با یک صفحه جدید ضمیمه شده و یک گزارش اعتبارسنجی MSLQ_highlighted_validation.xlsx تولید کرد.
Processing PDF: MSLQ.pdf
Scanning document for relevant information...
Questions not found:
Q1: I prefer class work that is challenging so I can learn new things.
Q50: When studying for this course, I often set aside time to discuss course material with a group of students from the class.
Q51: I treat the course material as a starting point and try to develop my own ideas about it.
Q61: I try to think through a topic and decide what I am supposed to learn from it rather than just reading it over when studying for this course.
Validation data saved to: MSLQ_highlighted_validation.xlsx
Highlighted PDF saved to: MSLQ_highlighted.pdf
Analysis Statistics:
- Questions found: 77
- Questions not found: 4
- Reversed items found: 8
- Scales found: 0
Process completed successfully!مجبور شدم REVERSED را به search_terms اضافه کنم تا برنامه در برجسته کردن موارد معکوس شده کمک کند.
هنوز میتوانیم ببینیم که ۴ سوال و مقیاس پیدا نشدند. بیایید بررسی کنیم.

اشکالزدایی برجستهسازیهای از دست رفته
سوال ۱
کلمات برجسته نشان میدهند که OCR آن را شناسایی کرده است. متن در تب اکسل نیز صحیح است.
اگرچه به نظر میرسد برنامه برجستهسازی در پیدیاف پیدا نشده است، اما در تب اکسل شناسایی شده است. به نظر میرسد مشکل در منطق برنامه برای برجستهسازی است و در دادههای استخراج شده نیست.
بیایید نگاهی به سوال ۵۰ بیندازیم:

سوال ۵۰
سوال ۵۰ به دلیل یک اشتباه OCR در search_terms پیدا نشد. "group of" به "group of" خوانده شد.
Q50: When studying for this course, I often set aside time to discuss course material with a group of students from the class.مشکلات مشابهی با سوالات دیگر نیز وجود داشت.
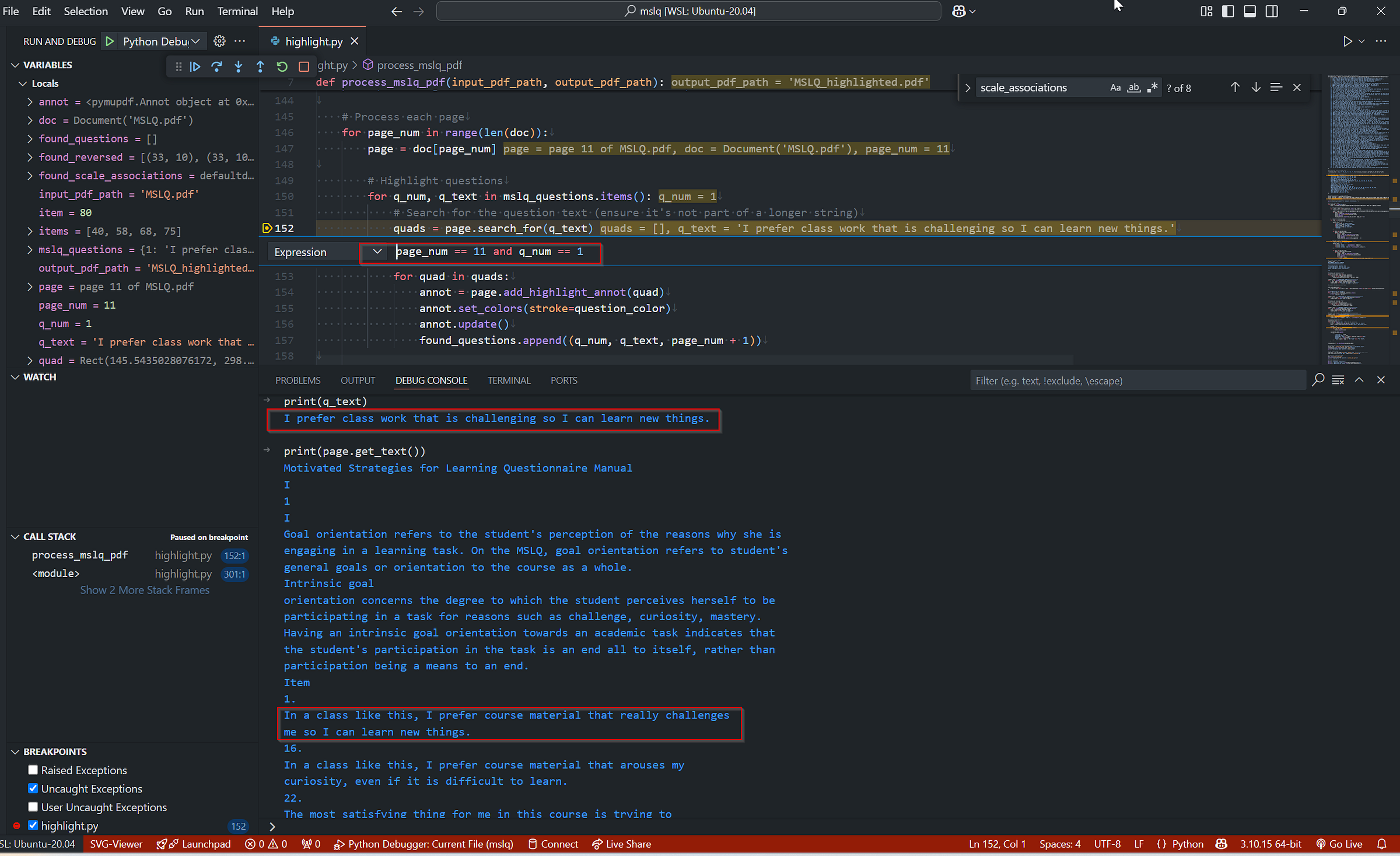
اشکالزدایی با نقاط توقف شرطی
بیایید کد را خط به خط با نقاط توقف اجرا کنیم.
import fitz # import PyMuPDF
pdf_document = fitz.open(pdf_path)
...
for page_num in range(len(pdf_document)):
page = pdf_document.load_page(page_num)
text = page.get_text("text")
for question_info in mslq_questions:
question_text = question_info[1]
if question_text in text: #<-- Breakpoint here!
...نقطه توقف را در خط if question_text in text: قرار میدهیم. این به ما امکان میدهد متن هر صفحه و متن هر سوال را که برنامه سعی در یافتن آن دارد، مشاهده کنیم. هر بار که برنامه یک سوال را در متن یک صفحه پیدا میکند، متوقف میشود.
اگر به متن سوال ۵۰ نگاه کنیم، میبینیم که حاوی عبارت "group of" است. اما اگر به متن استخراج شده OCR از صفحه حاوی سوال ۵۰ نگاه کنیم، میبینیم که OCR آن را "group of" خوانده است.
Q50: When studying for this course, I often set aside time to discuss course material with a group of students from the class.این همان دلیلی است که "group of" پیدا نشد. با استفاده از نقاط توقف شرطی، توانستیم تشخیص دهیم که مشکل در کیفیت پایین OCR بر روی متن اصلی است.
بینش شخصی
همانطور که منتظر بودم، نتایج آزمون من یک پروفایل انگیزشی و راهبردی متعادل را نشان داد. من انگیزه درونی بالایی دارم (بیشتر برای یادگیری خودم مطالعه میکنم تا نمرات)، اما گاهی اوقات برنامهریزی و نظم را به تعویق میاندازم. خودارزیابی من با یافتههای کلود مطابقت داشت.
این فرآیند به من نشان داد که چگونه یک ابزار قدیمی آموزشی را با هوش مصنوعی احیا کنم. دفعه بعد که با یک منبع ارزشمند قدیمی در قالبهای دست و پا گیر مواجه شدید، به جای ناامیدی، هوش مصنوعی را امتحان کنید.