با بهبود قابلیتهای مدل، مدلهای زبانی بزرگ (LLM) به طور فزایندهای در محیطها و گردشکارهای کاربر ادغام میشوند. به طور خاص، توسعهدهندگان نرمافزار با ابزارهای مجهز به LLM در محیطهای توسعه یکپارچه مانند VS Code، IntelliJ یا Eclipse کد مینویسند. در حالی که این ابزارها به طور فزایندهای در عمل مورد استفاده قرار میگیرند، ارزیابیهای LLM فعلی برای درک نحوه تعامل کاربران با این ابزارها در محیطهای واقعی با مشکل مواجه هستند، زیرا اغلب محدود به مطالعات کوتاه مدت کاربر هستند، فقط وظایف برنامهنویسی ساده را در مقابل سیستمهای دنیای واقعی در نظر میگیرند، یا به پلتفرمهای مبتنی بر وب متکی هستند که از محیطهای توسعه حذف شدهاند.
برای رفع این محدودیتها، ما کوپایلوت آرنا (Copilot Arena) را معرفی میکنیم، برنامهای که برای ارزیابی LLMها در محیطهای واقعی با جمعآوری ترجیحات مستقیماً در جریان کار واقعی یک توسعهدهنده طراحی شده است. کوپایلوت آرنا یک افزونه ویژوال استودیو کد (Visual Studio Code) است که به توسعهدهندگان، تکمیل خودکار کد را ارائه میدهد، مشابه نوع پشتیبانی ارائه شده توسط گیتهاب کوپایلوت (GitHub Copilot). تاکنون، بیش از 11000 کاربر کوپایلوت آرنا را دانلود کردهاند و این ابزار بیش از 100 هزار تکمیل کد را ارائه داده و بیش از 25000 نبرد تکمیل کد را جمعآوری کرده است. این نبردها یک جدول امتیازات زنده را در وبسایت LMArena وبسایت تشکیل میدهند. از زمان راهاندازی، کوپایلوت آرنا همچنین برای ارزیابی دو مدل جدید تکمیل کد قبل از انتشار آنها استفاده شده است: یک مدل کدسترال (Codestral) جدید از میسترال ایآی (Mistral AI) و مرکوری کودر (Mercury Coder) از اینسپشن ایآی (InceptionAI).
در این پست وبلاگ، ما در مورد نحوه طراحی و استقرار کوپایلوت آرنا بحث میکنیم. همچنین برجسته میکنیم که چگونه کوپایلوت آرنا بینشهای جدیدی در مورد ترجیحات کد توسعهدهنده ارائه میدهد.
طراحی سیستم کوپایلوت آرنا
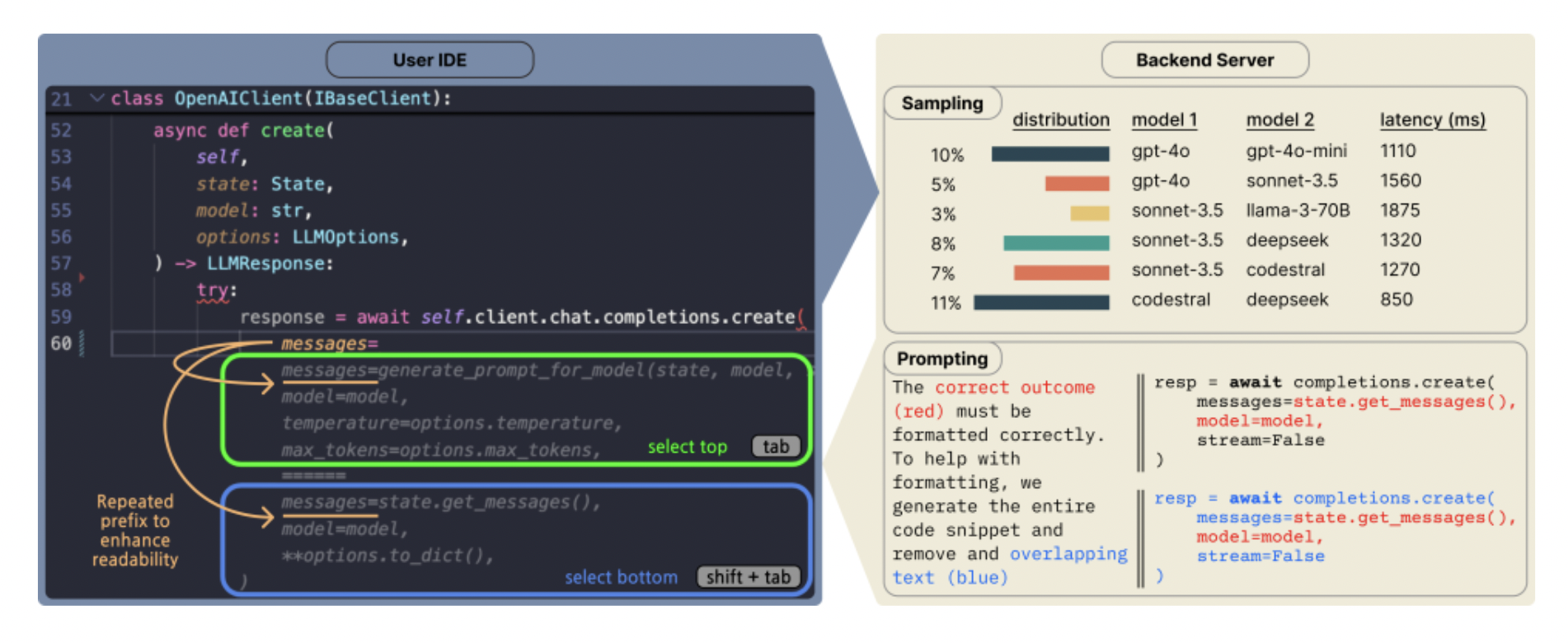
برای جمعآوری ترجیحات کاربر، کوپایلوت آرنا یک رابط کاربری جدید ارائه میدهد که به کاربران تکمیل کد جفتی از دو LLM مختلف را نشان میدهد، که بر اساس یک استراتژی نمونهبرداری تعیین میشوند که تأخیر را کاهش میدهد و در عین حال پوشش در مقایسههای مدل را حفظ میکند. علاوه بر این، ما یک طرحبندی درخواست را ابداع میکنیم که به مجموعهای متنوع از مدلها اجازه میدهد تا تکمیل کد را با دقت بالا انجام دهند. شکل 1 نمای کلی از این گردش کار را نشان میدهد. ما هر یک از اجزا را در زیر بررسی خواهیم کرد:
رابط کاربری: کوپایلوت آرنا به کاربران اجازه میدهد بین جفتهای تکمیل کد از LLMهای مختلف انتخاب کنند. انتخابهای کاربر به ما این امکان را میدهد تا درک بهتری از ترجیحات توسعهدهندگان بین LLMها داشته باشیم. برای جلوگیری از اختلال در گردش کار کاربر، رأیگیری به گونهای طراحی شده است که بدون مشکل باشد—کاربران از کلیدهای میانبر صفحه کلید برای پذیرش سریع تکمیل کد استفاده میکنند.
جفت مدلهای نمونهبرداری: ما یک استراتژی نمونهبرداری را بررسی میکنیم تا تأخیر تجربهشده را به حداقل برسانیم. از آنجایی که رابط کاربری ما دو تکمیل کد را با هم نشان میدهد، کندترین تکمیل، تأخیر را تعیین میکند. ما تأخیر هر مدل را به عنوان یک توزیع لگ-نرمال (log-normal) ثبت میکنیم و یک پارامتر دما را تنظیم میکنیم تا بین یک توزیع بهینهشده برای تأخیر و یک توزیع یکنواخت درونیابی کنیم، که کاهش 33 درصدی در میانگین تأخیر تجربهشده (از 1.61 به 1.07 ثانیه) در مقایسه با یک توزیع یکنواخت را مشاهده میکنیم.

درخواست برای تکمیل کد: در طول توسعه، مدلها باید "وسط را پر کنند"، جایی که کد باید بر اساس پیشوند و پسوند فعلی تولید شود. در حالی که برخی از مدلها، مانند دیپسیک (DeepSeek) و کدسترال (Codestral)، برای پر کردن وسط طراحی شدهاند، بسیاری از مدلهای چت اینطور نیستند و به درخواست اضافی نیاز دارند. برای انجام این کار، ما به مدل اجازه میدهیم قطعههای کد را تولید کند، که یک قالب طبیعیتر است، و سپس آنها را به یک تکمیل FiM پسپردازش میکنیم. رویکرد ما به شرح زیر است: علاوه بر الگوهای درخواست مشابه در بالا، به مدلها دستورالعمل داده میشود که با بازگرداندن بخشی از پیشوند شروع کرده و به طور مشابه با بخشی از پسوند پایان دهند. سپس بخشهایی از کد خروجی را در ورودی مطابقت میدهیم و کد تکراری را حذف میکنیم. این ترفند درخواست ساده به مدلهای چت اجازه میدهد تا تکمیل کد را با موفقیت بالایی انجام دهند (شکل 2).
استقرار

ما کوپایلوت آرنا را به عنوان یک افزونه رایگان در دسترس در فروشگاه افزونه VSCode مستقر میکنیم. در طول استقرار، ما قضاوتهای کاربر و تأخیر برای پاسخهای مدل را همراه با ورودی و تکمیل کاربر ثبت میکنیم. با توجه به ماهیت حساس برنامهنویسی، کاربران میتوانند دسترسی ما به دادههای خود را محدود کنند. بسته به تنظیمات حریم خصوصی، ما همچنین زمینه کد کاربر و پاسخهای مدل را جمعآوری میکنیم.
همانطور که در سایر کارهای مربوط به ارزیابی ترجیحات زوجی (pairwise preference evaluation) استاندارد است (به عنوان مثال، Chatbot Arena)، ما یک مدل بردلی-تری (Bradley-Terry) (BT) را برای تخمین قدرت نسبی هر مدل اعمال میکنیم. ما نبردها را در محاسبه BT بوتاسترپ میکنیم تا یک بازه اطمینان 95% برای رتبهبندیها ایجاد کنیم، که برای ایجاد یک جدول امتیازات استفاده میشوند که همه مدلها را رتبهبندی میکند، جایی که رتبه هر مدل با این واقعیت تعیین میشود که کران پایین کدام مدلهای دیگر زیر کران بالای آن قرار میگیرد. ما یک جدول امتیازات زنده از رتبهبندیهای مدل را در lmarena.ai میزبانی میکنیم (شکل 3).
یافتهها

مقایسه با مجموعه دادههای قبلی
ما جدول امتیازات خود را با ارزیابیهای موجود مقایسه میکنیم، که شامل جدول امتیازات ترجیحات زنده با بازخورد انسانی و معیارهای ثابت است (شکل 4). معیارهای ثابتی که با آنها مقایسه میکنیم عبارتند از LiveBench، BigCodeBench و LiveCodeBench، که تواناییهای تولید کد مدلها را در انواع وظایف پایتون ارزیابی میکنند و با انتشار مدلهای جدید به روز نگه داشته میشوند. ما همچنین با Chatbot Arena و زیرمجموعه کدنویسی خاص آنها مقایسه میکنیم، که ترجیحات انسانی پاسخهای چت جمعآوری شده از طریق یک پلتفرم وب هستند.
ما همبستگی پایینی (r = 0.1) با اکثر معیارهای ثابت پیدا میکنیم، اما همبستگی نسبتاً بالاتری (همبستگی رتبه اسپیرمن (r) 0.62) با Chatbot Arena (کدنویسی) و همبستگی مشابهی (r = 0.48) با Chatbot Arena (عمومی). همبستگی قویتر با ارزیابیهای ترجیحات انسانی در مقایسه با معیارهای ثابت احتمالاً نشان میدهد که بازخورد انسانی جنبههای متمایز عملکرد مدل را ثبت میکند که معیارهای ثابت قادر به اندازهگیری آن نیستند. ما متوجه میشویم که مدلهای کوچکتر تمایل به عملکرد بیش از حد دارند (به عنوان مثال، GPT-4o mini و Qwen-2.5-Coder 32B)، به ویژه در معیارهای ثابت. ما این تفاوتها را به توزیع منحصر به فرد دادهها و وظایفی که کوپایلوت آرنا بر روی آنها ارزیابی میکند نسبت میدهیم، که در ادامه با جزئیات بیشتری به بررسی آن میپردازیم.

توزیع منحصر به فرد وظایف در کوپایلوت آرنا
کوپایلوت آرنا دادههای خود را مستقیماً از جریان کار توسعهدهندگان جمعآوری میکند، که منجر به توزیع متفاوتی از کدها میشود. به طور خاص، کوپایلوت آرنا زبانهای مختلفی را پوشش میدهد (شکل 5a) و اغلب نیاز به تولید در واردات طولانی دارد (شکل 5b)، که میتواند برای مدلهای کوچکتر چالشبرانگیز باشد.
مورد استفاده در دنیای واقعی: ارزیابی قبل از انتشار
کوپایلوت آرنا برای ارزیابی تجربیات قبل از انتشار استفاده شد. در عرض دو هفته، این ابزار بیش از 20000 رای را جمعآوری کرد و بینشی در مورد مزایا و معایب نسبی عملکرد هر مدل ارائه داد. برای این مطالعه، به طور خاص به یک تغییر در نحوه درخواست خودکار وارداتها علاقه داشتیم و نتایج به ما در مورد پارامترهای این قابلیت هشدار داد.
گامهای بعدی
در این پست وبلاگ، ما کوپایلوت آرنا را معرفی کردیم، یک برنامه برای ارزیابی LLMها برای کد. ما برنامهریزی داریم که ویژگیهای زیر را اضافه کنیم:
- رابطهای کاربری بیشتر: توسعهدهندگان به روشهای مختلفی از افزونه ما استفاده میکنند، بنابراین ما قصد داریم ارزیابیهای ریزدانهتر را در مورد موارد استفاده مانند تولید آزمون واحد و تکمیل سطح خط فعال کنیم.
- مدلهای قابل اتصال: مشتریان اغلب مدلهای خود را دارند که میخواهند از آنها استفاده کنند. ما قصد داریم این گزینه را باز کنیم.
از کوپایلوت آرنا استفاده کنید
اگر میخواهید کوپایلوت آرنا را امتحان کنید، آن را از فروشگاه افزونه VSCode دانلود کنید. اگر علاقهمند به استفاده از کوپایلوت آرنا برای ارزیابیهای قبل از انتشار هستید، با [email protected] تماس بگیرید.
این پست وبلاگ بر اساس کار زیر است:
کوپایلوت آرنا: ارزیابی LLMها برای کد با جمعآوری ترجیحات انسانی
وین چی، والری چن، کریس دوناهو، آمیت تالوالکار
ما از کای یانگ، جیم وو، میشل وونگ، جویوس جو، ریویا سوندراراجان و کیت گندره به خاطر نظراتشان تشکر میکنیم. این کار با حمایت بنیاد آلفرد پی. اسلون (Alfred P. Sloan Foundation)، گوگل، اناساف (NSF)، و از طریق کمک مالی با شماره 232130288 از بنیاد تحقیقاتی آمازون (Amazon Research Award) انجام شد.