
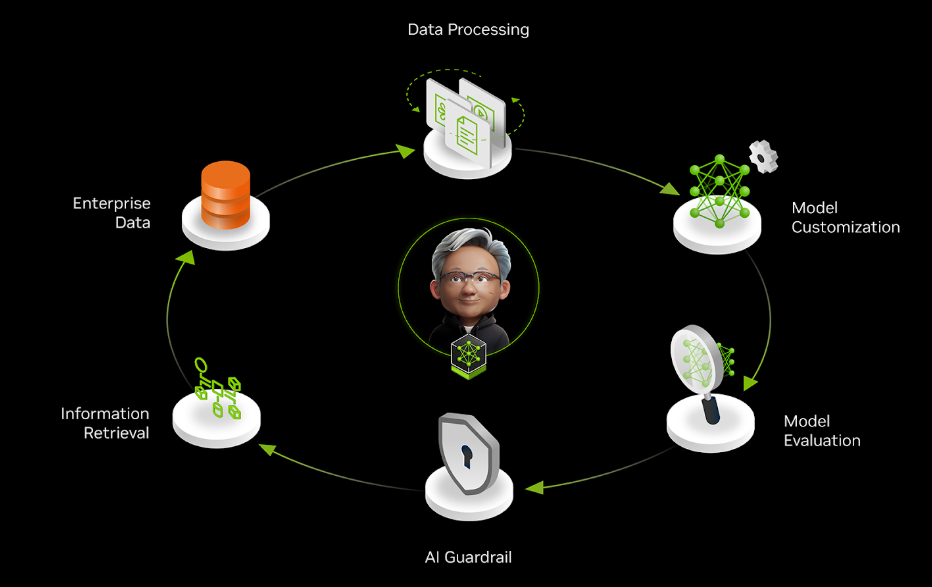
چرا چرخههای داده برای هوش مصنوعی عاملمحور حیاتی هستند؟
دادههای سازمانی به طور مداوم در حال تغییر هستند. این امر چالشهای مهمی را برای حفظ دقت سیستم هوش مصنوعی در طول زمان ایجاد میکند. از آنجایی که سازمانها به طور فزایندهای به سیستمهای هوش مصنوعی عاملمحور برای بهینهسازی فرآیندهای تجاری متکی هستند، همسو نگه داشتن این سیستمها با نیازهای تجاری در حال تحول و دادههای جدید بسیار مهم میشود.
این پست به بررسی چگونگی ساخت یک تکرار از چرخه داده با استفاده از NVIDIA NeMo microservices، با یک مرور سریع از مراحل ساخت یک پایپلاین end-to-end میپردازد.
برای بررسی اینکه چگونه NeMo microservices میتواند برای رفع چالشهای مختلف هنگام ساخت یک چرخه داده استفاده شود، به بهینهسازی عملکرد عامل هوش مصنوعی با استفاده از NVIDIA NeMo Microservices مراجعه کنید.
نیاز به انطباق مداوم
در محیطهای تولید، برنامههای هوش مصنوعی با یک چالش مداوم روبرو هستند: رانش مدل (model drift). یک عامل هوش مصنوعی را در نظر بگیرید که پرسشهای کاربر را به سیستمهای متخصص تخصصی هدایت میکند. ورودیهای این سیستم، ابزارهایی که از آنها استفاده میکند و پاسخهای آنها به طور مداوم در حال تحول هستند. بدون یک مکانیسم برای انطباق، دقت به ناچار به دلیل موارد زیر کاهش مییابد:
- بهروزرسانی پایگاههای دانش و مستندات سازمانی
- تغییر رفتار کاربر و الگوهای پرسش
- تغییر APIها و پاسخهای ابزار
به عنوان مثال، یک عامل مدل زبانی بزرگ (LLM) بانکی که با پرسوجو از یک پایگاه داده SQL تراکنش (PostgreSQL) به سؤالات مشتری پاسخ میدهد، زمانی که سازمان یک مجموعه داده MongoDB جدید با یک شمای متفاوت اضافه میکند و قالب پاسخ خود را بهروزرسانی میکند، با چالشهای مهمی روبرو میشود. بدون آموزش مجدد، عامل به فرمولبندی پرسوجوها برای ساختار پایگاه داده قدیمی ادامه میدهد، که منجر به بازیابیهای ناموفق یا اطلاعات نادرست میشود. این به اعتماد مشتری آسیب میرساند و به طور بالقوه مسائل مربوط به انطباق را ایجاد میکند.
نیاز به کارایی
از آنجایی که این عوامل در پیچیدگی رشد میکنند تا وظایف پیچیدهتری را انجام دهند، حفظ دقت و ارتباط حتی چالشبرانگیزتر میشود. علاوه بر این، با افزایش حجم تراکنشها، هزینه محاسباتی ارائه این مدلها به طور قابل توجهی افزایش مییابد و کارایی را به یک نگرانی حیاتی تبدیل میکند. این امر به ویژه برای سیستمهای هوش مصنوعی عاملمحور مشکلساز است، زیرا آنها اغلب به چندین گذر استنتاج برای استدلال، برنامهریزی و مراحل اجرا نیاز دارند - در مقایسه با مدلهای استنتاج تکگذر ساده، بار محاسباتی را چند برابر میکنند.
هنگامی که یک عامل باید چندین اقدام بالقوه را ارزیابی کند، از منابع دانش متعدد پرسوجو کند و خروجیهای خود را اعتبارسنجی کند، هر تعامل میتواند به 5 تا 10 برابر بیشتر از استنتاج مدل استاندارد نیاز داشته باشد و هزینههای زیرساختی را با مقیاسبندی استفاده به طور چشمگیری افزایش دهد.
با استفاده از تکنیکهای سفارشیسازی، میتوانید مدلهای کوچکتر را بهینه کنید تا با دقت مدلهای بسیار بزرگتر مطابقت داشته باشند، بنابراین تأخیر و هزینه کل مالکیت (TCO) را کاهش دهید. علاوه بر این، از آنجایی که مدلهای جدیدتر و توانمندتر ظاهر میشوند، ارزیابی مداوم این مدلها (در کنار انواع دقیق تنظیمشده آنها)، با استفاده از دادههای تعامل کاربر میتواند عملکرد و سازگاری پایدار را تضمین کند.
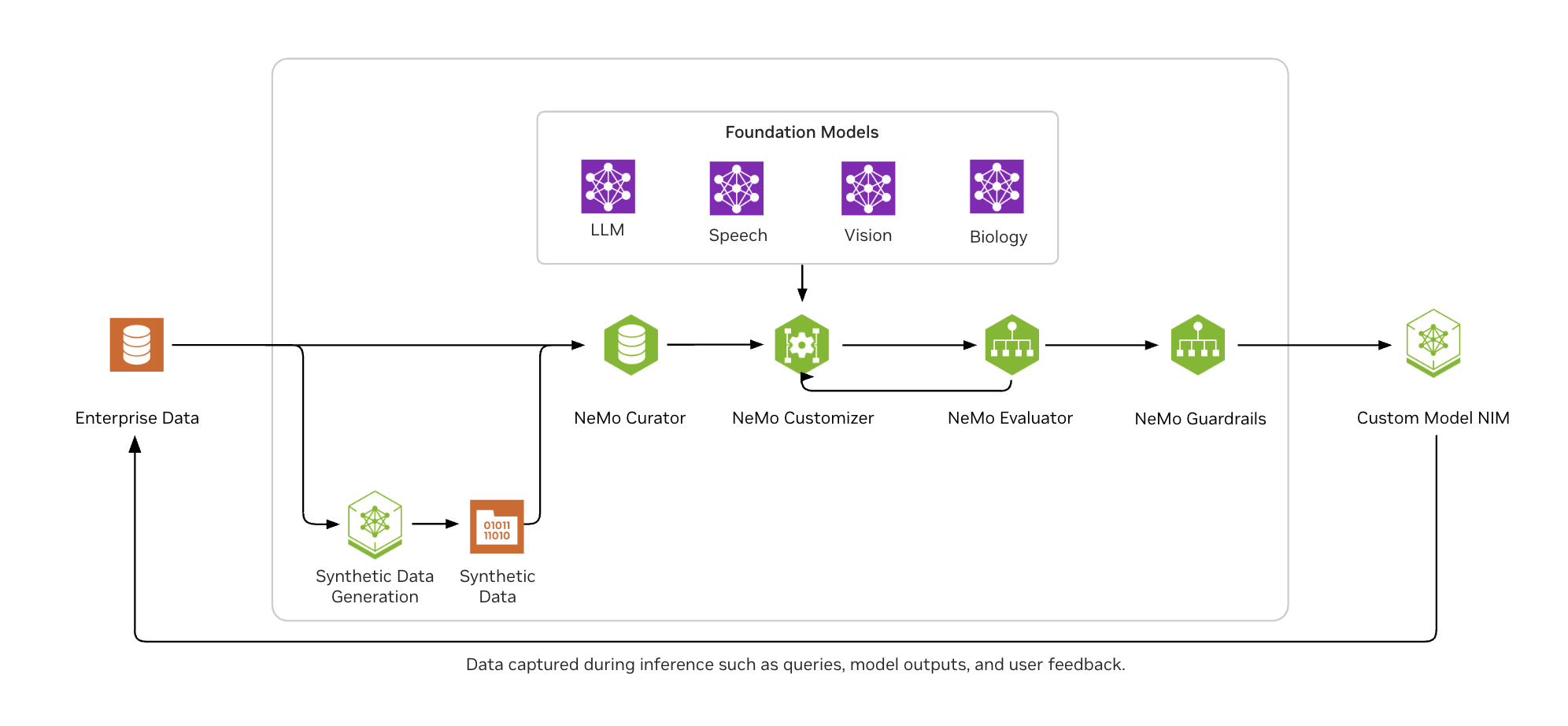
استفاده از NVIDIA NeMo microservices برای تامین انرژی چرخه داده شما
NVIDIA NeMo microservices یک پلتفرم end-to-end برای ساخت چرخههای داده فراهم میکند و شرکتها را قادر میسازد تا به طور مداوم عوامل هوش مصنوعی خود را با آخرین اطلاعات بهینه کنند.
همانطور که در شکل 2 نشان داده شده است، NVIDIA NeMo به توسعهدهندگان هوش مصنوعی سازمانی کمک میکند تا به راحتی دادهها را در مقیاس وسیع انتخاب کنند، مدلهای LLM را با تکنیکهای دقیق تنظیم محبوب سفارشی کنند، به طور مداوم مدلها را بر روی بنچمارکهای صنعتی و سفارشی ارزیابی کنند و آنها را برای خروجیهای مناسب و پایدار محافظت کنند.
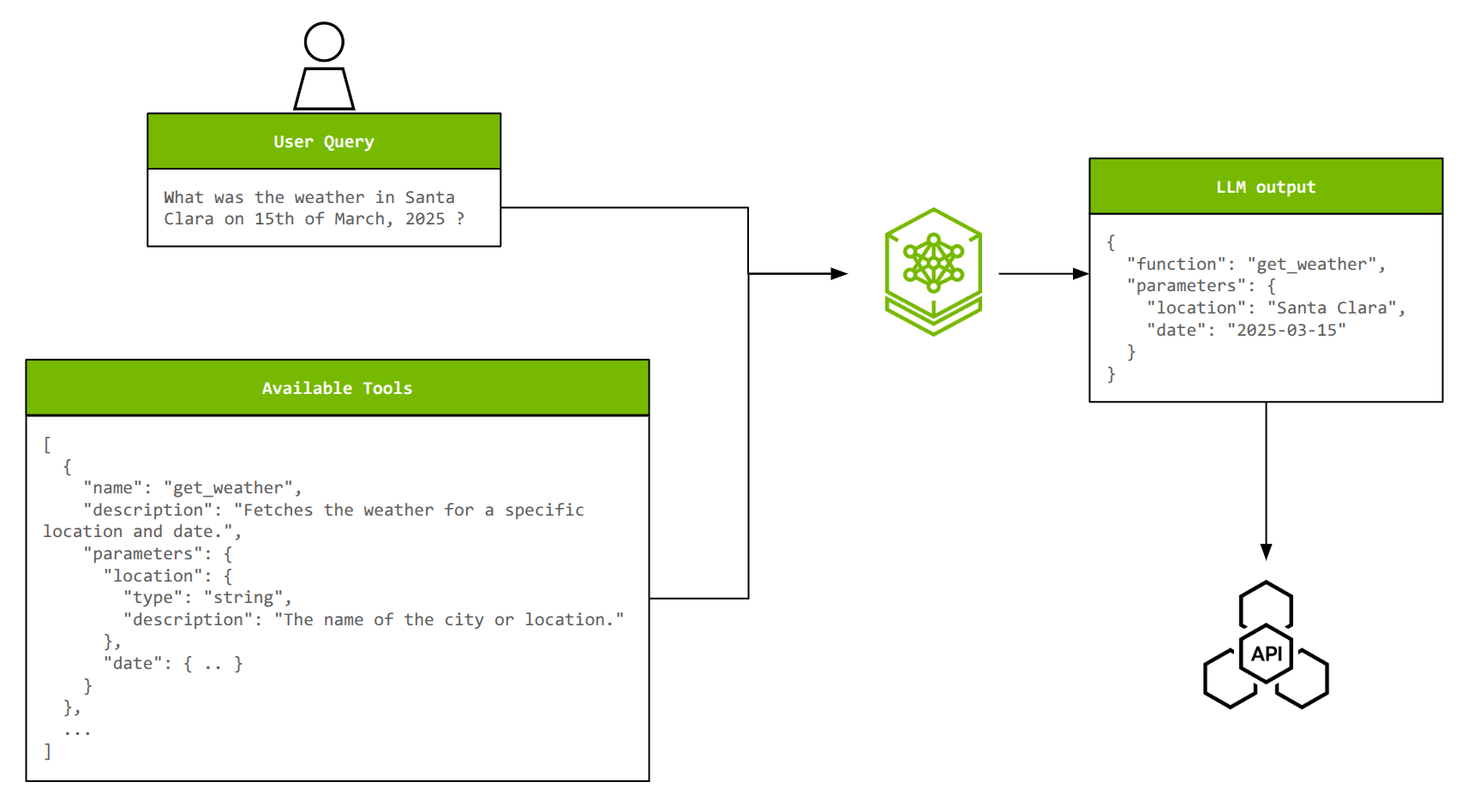
نمونه کد برای بهبود فراخوانی ابزار عامل با NeMo microservices
برای نشان دادن یک پایپلاین end-to-end با NeMo microservices، مثال فراخوانی ابزار در عوامل را در نظر بگیرید. فراخوانی ابزار، مدلهای LLM را قادر میسازد تا با سیستمهای خارجی تعامل داشته باشند، برنامهها را اجرا کنند و به اطلاعات بیدرنگ که در دادههای آموزشی آنها در دسترس نیست، دسترسی داشته باشند.
برای فراخوانی ابزار مؤثر، یک LLM باید ابزار صحیح را از گزینههای موجود انتخاب کند، پارامترهای مناسب را از پرسشهای زبان طبیعی استخراج کند و به طور بالقوه چندین عمل را به هم زنجیر کند یا چندین ابزار را به طور موازی فراخوانی کند. با افزایش تعداد ابزارها و پیچیدگی آنها، سفارشیسازی برای حفظ دقت و کارایی حیاتی میشود.
با تنظیم دقیق یک مدل Llama 3.2 1B Instruct بر روی مجموعه داده xLAM (~60,000 مثال فراخوانی ابزار)، میتوان به دقت فراخوانی ابزار نزدیک به یک مدل Llama 3.1 70B Instruct دست یافت و در نتیجه اندازه مدل را 70 برابر کاهش داد.
بخشهای زیر مراحل کلیدی را برای ارائه یک مرور سریع به شما شرح میدهند. آموزش کامل را در Jupyter notebooks بررسی کنید.
مرحله 1: استقرار NVIDIA NeMo microservices
پلتفرم NeMo microservices در قالب نمودارهای Helm موجود است که میتوان آنها را بر روی سیستم دارای Kubernetes مورد نظر خود مستقر کرد. برای شروع، میتوانید از minikube بر روی یک خوشه NVIDIA GPU تک گره با حداقل دو NVIDIA GPU (NVIDIA A100 80 GB یا NVIDIA H100 80 GB) استفاده کنید.
مرحله 2: آمادهسازی داده
مجموعه داده xLAM به فرمتهای سازگار با NeMo Customizer برای آموزش و NeMo Evaluator برای آزمایش تبدیل میشود. هر نمونه داده یک شی json است - متشکل از یک پرسش کاربر، لیستی از ابزارهای موجود (همراه با توضیحات و پارامترهای آنها) و پاسخ حقیقت اصلی (یک ابزار انتخابشده با پارامترها). علاوه بر این، تقسیمات داده برای آموزش، اعتبارسنجی و آزمایش ایجاد میشوند.
فرمت داده برای NeMo Customizer در زیر نشان داده شده است. توجه داشته باشید که messages شامل پرسش
کاربر و پاسخ حقیقت اصلی دستیار است و tools شامل لیستی از ابزارهای موجود برای انتخاب است.
{
"messages": [
{
"role": "user",
"content": "Where can I find live giveaways for beta access?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_beta",
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"arguments": {"type": "beta"}
}
},
]
}
],
"tools": [
{
"type": "function",
"function": {
"name": "live_giveaways_by_type",
"description": "Retrieve live giveaways from the GamerPower API based on the specified type.",
"parameters": {
"type": "object",
"properties": {
"type": {
"type": "string",
"description": "The type of giveaways to retrieve (e.g., game, loot, beta).",
"default": "game"
}
},
"required": []
}
}
}
]
}NeMo Evaluator این فرمت را بسیار نزدیک دنبال میکند، با یک تفاوت جزئی. اطلاعات بیشتر را میتوان در Jupyter notebook یافت.
مرحله 3: مدیریت موجودیت
NVIDIA NeMo Entity Store microservice موجودیتهای سازمانی مانند فضاهای نام، پروژهها، مجموعههای داده و مدلها را مدیریت میکند و یک ساختار سلسله مراتبی برای مدیریت کارآمد منابع ارائه میدهد. با انجام این کار، همکاری یکپارچه را فعال میکند و از تضادهای منابع در بین چندین کاربر جلوگیری میکند. از طرف دیگر، NVIDIA NeMo Datastore microservice، فایلهای واقعی مرتبط با این موجودیتها را مدیریت میکند و از عملیاتی مانند آپلود، دانلود و نسخهسازی پشتیبانی میکند.
در این مرحله، مجموعههای داده آمادهشده از طریق ادغام پشتیبانیشده خود با رابط Hugging Face Hub (HfApi) در NeMo Datastore آپلود میشوند و از طریق فراخوانیهای REST API در Entity Store و Datastore ثبت میشوند. NeMo Customizer و Evaluator به این مسیرها برای ورودیهای خود ارجاع میدهند.
مرحله 4: تنظیم دقیق انطباق با رتبه پایین (LoRA)
NeMo Customizer برای تنظیم دقیق LoRA مدل Llama 3.2 1B Instruct استفاده میشود. راهاندازی یک کار سفارشیسازی و نظارت بر وضعیت کار نیز فراخوانیهای REST API به نقطه پایانی NeMo Customizer است. پارامترهای آموزشی را میتوان مانند هر کار آموزشی یادگیری عمیق دیگری پیکربندی کرد. علاوه بر این، NeMo Customizer به طور یکپارچه با Weights & Biases برای نظارت بر اجراهای آموزشی ادغام میشود.
headers = {"wandb-api-key": WANDB_API_KEY} if WANDB_API_KEY else None
training_params = {
"name": "llama-3.2-1b-xlam-ft",
"output_model": f"{NAMESPACE}/llama-3.1-8b-xlam-run1",
"config": BASE_MODEL,
"dataset": {"name": DATASET_NAME, "namespace" : NAMESPACE},
"hyperparameters": {
"training_type": "sft",
"finetuning_type": "lora",
"epochs": 2,
"batch_size": 16,
"learning_rate": 0.0001,
"lora": {
"adapter_dim": 32,
"adapter_dropout": 0.1
}
}
}
# Trigger the job.
resp = requests.post(f"{NEMO_URL}/v1/customization/jobs", json=training_params, headers=headers)
customization = resp.json()
# Used to track status
JOB_ID = customization["id"]
# This will be the name of the model that will be used to send inference queries to
CUSTOMIZED_MODEL = customization["output_model"]مرحله 5: استنتاج
هنگامی که مدل آموزش داده شد، آداپتور LoRA آن در NeMo Entity Store ذخیره میشود و به طور خودکار توسط NVIDIA NIM انتخاب میشود. میتوانید مدل را با ارسال یک prompt به نقطه پایانی NIM آن آزمایش کنید.
inference_client = OpenAI(
base_url = f"{NIM_URL}/v1",
api_key = "None"
)
completion = inference_client.chat.completions.create(
model = CUSTOMIZED_MODEL,
messages = test_sample["messages"],
tools = test_sample["tools"],
tool_choice = 'auto',
temperature = 0.1,
top_p = 0.7,
max_tokens = 512,
stream = False
)
print(completion.choices[0].message.tool_calls)این باید خروجی را تولید کند که شامل نام ابزار همراه با پر کردن پارامترهای آن باشد:
[ChatCompletionMessageToolCall(id='chatcmpl-tool-bd3e4ee65e0641b7ae2285a9f82c7aae',
function=Function(arguments='{"type": "beta"}', name='live_giveaways_by_type'), type='function')]در این مرحله، مدل برای ارزیابی برای کمیت دقت آن در فراخوانی ابزار آماده است.
مرحله 6: ارزیابی
مدل تنظیمشده دقیق با استفاده از NeMo Evaluator ارزیابی میشود و دقت آن در برابر مدل پایه مقایسه میشود. معیارهایی
مانند function_name_accuracy و function_name_and_args_accuracy پیشرفتها را در
قابلیت فراخوانی ابزار برجسته میکنند. این معیارها، همانطور که از نام آنها پیداست، دقت تطبیق رشته را برای نام توابع و
آرگومانهای آنها محاسبه میکنند.
ارزیابی به طور کلی از قسمتهای زیر تشکیل شده است:
1. ایجاد یک پیکربندی ارزیابی: این به NeMo Evaluator جزئیاتی در مورد ارزیابی مورد نظر شما مانند مجموعه داده برای استفاده، تعداد نمونههای آزمایشی، معیارها و موارد دیگر میگوید.
simple_tool_calling_eval_config = {
"type": "custom",
"tasks": {
"custom-tool-calling": {
"type": "chat-completion",
"dataset": {
"files_url": f"hf://datasets/{NAMESPACE}/{DATASET_NAME}/testing/xlam-test.jsonl",
"limit": 50
},
"params": {
"template": {
"messages": "{{ item.messages | tojson}}",
"tools": "{{ item.tools | tojson }}",
"tool_choice": "auto"
}
},
"metrics": {
"tool-calling-accuracy": {
"type": "tool-calling",
"params": {"tool_calls_ground_truth": "{{ item.tool_calls | tojson }}"}
}
}
}
}
}2. راهاندازی کار ارزیابی: این شامل تعیین پیکربندی ارزیابی، همراه با مدل سفارشی (NIM) است که باید ارزیابی کند.
res = requests.post(
f"{NEMO_URL}/v1/evaluation/jobs",
json= {
"config": simple_tool_calling_eval_config,
"target": {"type": "model", "model": CUSTOM_MODEL_NAME}
}
)
base_eval_job_id = res.json()["id"]3. بررسی معیارهای ارزیابی: پس از اتمام کار ارزیابی، بررسی معیارها نیز یک فراخوانی REST است.
res = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{base_eval_job_id}/results")
ft_function_name_accuracy_score = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_accuracy"]["value"]
ft_function_name_and_args_accuracy = res.json()["tasks"]["custom-tool-calling"]["metrics"]["tool-calling-accuracy"]["scores"]["function_name_and_args_accuracy"]["value"]
اگر نوتبوک نمایشی ارائهشده را دنبال کنید، باید در مقایسه با مدل پایه meta/llama-3.2-1B-instruct
افزایش قابل توجهی را مشاهده کنید. تقریباً میتوانید انتظار داشته باشید:
function_name_accuracy: 12% به 92%function_name_and_args_accuracy: 8% به 72%
این بسیار نزدیک به دقت پایه meta/llama-3.1-70B-instruct در این کار است، مدلی که 70 برابر بزرگتر
از آن است.
مرحله 7: محافظت
آخرین بخش این پایپلاین اضافه کردن محافظ به NIM مدل سفارشی شما است. در این مورد، ما با استفاده از
nvidia/llama-3_1-nemoguard-8b-content-safety،
ایمنی محتوا را اعمال میکنیم که محتوای تعامل انسان و LLM را تعدیل میکند و promptهای کاربر و پاسخهای LLM را
به عنوان ایمن یا ناایمن طبقهبندی میکند. اگر محتوا ناایمن باشد، مدل علاوه بر این، پاسخی با لیستی از دستههایی که
محتوا نقض میکند، برمیگرداند.
مشابه ارزیابی، این از موارد زیر تشکیل شده است:
1. ایجاد و ثبت یک پیکربندی محافظ: توجه داشته باشید که مدل از دستههای ناایمن برای تشخیص، همراه با فرمت پاسخ آن مطلع میشود.
data = {
"name": "toolcalling",
"namespace": "default",
"data": {
"models": [
{
"type": "content_safety",
"engine": "nim",
"model": "nvidia/llama-3.1-nemoguard-8b-content-safety"
}
],
"rails": {
"input": {
"flows": [
"content safety check input $model=content_safety"
]
},
"dialog": {
"single_call": {
"enabled": False
}
}
},
"prompts": [
{
"task": "content_safety_check_input $model=content_safety",
"messages": [
{
"type": "system",
"content": "Task: Check if there is unsafe content in the user or agent messages in the below conversation in accordance with our
safety policy with the below categories. Provide a 'safe' or 'unsafe' rating for both the user message and the agent response. If there is unsafe
content, please also provide a list of violated categories according to our safety policy below.\n\n\nS1: Violence.\nS2: Sexual.\nS3: Criminal Planning/Confessions.\nS4: Guns and Illegal Weapons.\nS5: Controlled/Regulated
Substances.\nS6: Suicide and Self Harm.\nS7: Sexual (minor).\nS8: Hate/Identity Hate.\nS9: PII/Privacy.\nS10: Harassment.\nS11: Threat.\nS12:
Profanity.\nS13: Needs Caution.\nS14: Other.\nS15: Manipulation.\nS16: Fraud/Deception.\nS17: Malware.\nS18: High Risk Gov Decision
Making.\nS19: Political/Misinformation/Conspiracy.\nS20: Copyright/Trademark/Plagiarism.\nS21: Unauthorized Advice.\nS22: Illegal
Activity.\nS23: Immoral/Unethical.\nS24: Deleting Logs.\n\n\n\nuser:
{{user_query}}\n\n\nProvide your safety assessment for the above conversation in the below output JSON
format:\n{\"User Safety\": safe or unsafe rating for the user message, \"Response Safety\": safe or unsafe rating for the agent response.
Omit if no agent response present. \"Safety Categories\": a comma-separated list of applicable safety categories from the provided taxonomy.
Omit if all safe.}\n\nDo not include anything other than the output JSON in your response.\nOutput JSON:"
},
{
"type": "user",
"content": "{{ user_input }}"
}
],
"output_parser": "nemoguard_parse_prompt_safety",
"max_tokens": 50
}
]
},
}
# Register the guardrails configuration
response = requests.post(GUARDRAILS_URL, json=data) 2. افزودن محافظ به ورودی کاربر قبل از فراخوانی استنتاج LLM NIM
payload = {
"model": BASE_MODEL,
"messages": [
{
"role": "user",
"content": user
input
}
]
}
# Pass the user content through the guardrails
response = requests.post(f"{GUARDRAILS_URL}/evaluate", json=payload).json()
guardrails_result = response["evaluation"]["content_safety"]در صورت ناایمن بودن محتوا، پاسخ JSON باید این دستهها را لیست کند. به عنوان مثال:
{"User Safety": "unsafe", "Safety Categories": "S12: Profanity"}اکنون میتوانید با خیال راحت این پایپلاین را به کار ببرید، دانستن اینکه مدل شما با دادههای بهروز و محافظها تقویت میشود. علاوه بر این، میتوانید آزمایش خودکار دادههای سازمانی و سفارشیسازیهای مدل را تنظیم کنید تا به طور مداوم در جهت یک سیستم با عملکرد بهتر تکامل پیدا کنید.
جلو
در این پست، چگونگی ساخت یک پایپلاین end-to-end برای ارائه یک چرخه داده کارآمد برای هوش مصنوعی عاملمحور با استفاده از NVIDIA NeMo microservices را مورد بحث قرار دادیم. ما تکنیکهای سفارشیسازی برای بهبود فراخوانی ابزار در عاملها را به طور کامل نشان دادیم و اطمینان حاصل کردیم که میتوان آنها را در کنار محافظهای ایمنی مناسب به کار گرفت.
امروز سفر چرخه داده خود را با NVIDIA NeMo microservices آغاز کنید.