
چند هفته پس از انتشار پر فراز و نشیب Llama 4، به نظر میرسد جامعه باز بیشتر بر شایعات Qwen 3 تمرکز دارد تا اینکه بخواهد بر روی این مدلها بنا کند - بیشتر به دلیل اندازه آنها و نه به دلیل عرضه گیجکنندهاش. هفته آینده LlamaCon است، بنابراین باید انتظار مدلهای بیشتری را داشته باشیم.
این وقفه زمانی خوبی است تا بپرسیم - این همه مدل استدلال باز به کجا میروند؟ دیگر داشتن یک مدل دیگر که بر روی AIME صعود میکند یا یک DeepSeek R1 دیگر برای چیزی، هیجانانگیز نیست. برخی از مدلها وارد وظایف کدنویسی و عاملیتی میشوند، اما به نظر میرسد سیستمهایی که از این مدلها استفاده میکنند، تاثیرگذارتر از مجموعه دادههای فردی خواهند بود. این امر تنها با میزان متفاوت و تغییر دهنده انتظارات انتشار o3 با ابزارها به صورت بومی تقویت میشود.
ما به پوشش این تحولات ادامه خواهیم داد و اگر مصنوعات باز به این شکل استفاده میشوند، پیوندهای پروژه بیشتری را نسبت به پیوندهای HuggingFace اضافه خواهیم کرد. این امر با پوشش ما از نحوه عبور مدلهای باز از آستانههای قابلیت مهم همسو است.
خواندن این موضوع فقط تکرار میکند که بزرگترین و بهترین انتشارات باز هنوز هم بیشترین تأثیر را دارند. شکستن و تبدیل شدن به یک استاندارد صنعتی مانند R1 یا Llama 3 یا Qwen 2.5 دشوار است.
همچنین، اولین پیشنویس کتاب RLHF که من (Nathan) روی آن کار کردهام به پایان رسیده است (نسخه وب، نسخه Arxiv). این کتاب چیزهای بیشتری نسبت به RLHF دارد، مانند بازخورد هوش مصنوعی، هوش مصنوعی مشروطه، مروری بر تقطیر و سوالات باز مرتبط. این کتاب به گونهای طراحی شده است که لذتبخش و مفید باشد تا کامل. در اواخر سال جاری میتوانید ایمیلی دریافت کنید که اعلام میکند پیشسفارشها برای نسخههای فیزیکی باز است، پس با ما همراه باشید.
در این شماره، ما تحت تأثیر مشارکتهای اخیر Nvidia در اکوسیستم باز قرار گرفتهایم، و شاهد کارهای RAG/embedding زیادی هستیم که برای کاربردهای سازمانی مدلهای باز ضروری هستند، و از میزان شرکتهای چینی که مدلهای شگفتانگیزی را منتشر میکنند، متعجب نیستیم (این یک هنجار است).
گزینههای ما
- Llama-3_1-Nemotron-Ultra-253B-v1 توسط nvidia: یک مدل استدلال که بر اساس نسخه هرس شده Llama 3.1 ساخته شده است. پس از هرس کردن، آنها چندین دور پسآموزش را انجام میدهند: با SFT (با استفاده از Llama، Qwen، QwQ و R1) شروع میکنند، و به دنبال آن چندین دور RL، هم برای قابلیتها و هم برای همسویی. جدا از نوع 253B، آنها همچنین یک مدل 49B [از Llama 70B] و یک مدل 8B را منتشر میکنند.
- Kimi-VL-A3B-Instruct توسط moonshotai: یک MoE دیداری از Moonshot AI / Kimi، که تحت مجوز MIT منتشر شده است. عملکرد این مدل واقعاً محکم به نظر میرسد و با Qwen2.5 VL-7B همتراز است، در حالی که از نیمی از پارامترهای فعال استفاده میکند (اما دو برابر پارامترهای کل). آنها همچنین یک نسخه تفکر را منتشر میکنند و امتیازات را حتی بیشتر افزایش میدهند. در گزارش فنی خود، آنها بیان میکنند که مدلهای بزرگتری را بر روی دادههای بیشتری آموزش خواهند داد. با توجه به اینکه Moonshot AI یکی از سوپراستارهای فضای LLM چین است، این تیم و سری مدلها یک مورد برای زیر نظر داشتن است. همچنین به روندی که مشاهده کردیم ادامه میدهد: آزمایشگاهها و شرکتهای بزرگ چینی به انتشار مدلهای بسیار توانمند تحت مجوزهای OSS مجاز، معمولاً MIT یا Apache 2.0، ادامه میدهند.
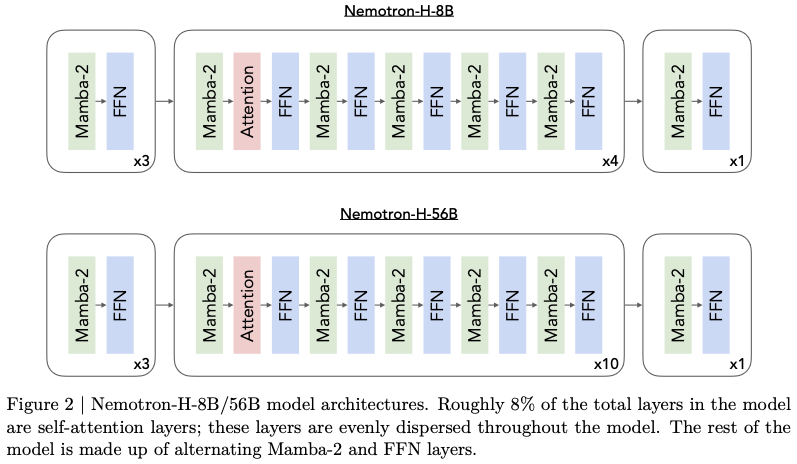
- Nemotron-H-56B-Base-8K توسط nvidia: یک مدل ترکیبی ترانسفورماتور-مامبا که بر روی 20T توکن آموزش داده شده است. گزارش به جزئیات بیشتری میپردازد. این مدلها در همان سطح یک نوع فقط توجه عمل میکنند، در حالی که بیش از دو برابر سریعتر هستند. معیارهای بافت طولانی نیز رقابتی به نظر میرسند و این معماری را به یک رقیب جدی برای جایگزینی مدلهایی که از توجه پنجره کشویی یا انواع مشابه استفاده میکنند، تبدیل میکند. با این حال، مدلهای منتشر شده فقط از بافت 8K پشتیبانی میکنند.
- GLM-Z1-Rumination-32B-0414 توسط THUDM: یک مدل آموزش داده شده برای تحقیقات (عمیق). این مدل توسط تیمی آموزش داده شده است که پشت GLM و CogView قرار دارند و نام خود را به Z AI تغییر دادهاند. این مدل را میتوان در وبسایت آنها برای امتحان کردن آن دسترسی داشت. این مدل خاص برای جستجو و کلیک از طریق وبسایتها با چندین فراخوانی عملکرد در طول قسمت استدلال خود آموزش داده شده است.
- mrcr توسط openai: OpenAI هفته پرماجرایی را با انتشار سری GPT-4.1 و o3 / o4-mini داشت. با این حال، این همه چیزهایی نیست که آنها رها کردند. آنها همچنین یک رقیب منبع باز برای claude-code به نام codex (نباید با مدل کدنویسی به همین نام اشتباه شود) و دو معیار بافت طولانی: MRCR، یک تکرار باز از معیار Google، و GraphWalks را منتشر کردند.
پیوندها
- دوستان ما در General Reasoning یک پست وبلاگی در مورد آنچه برای مقیاسبندی محاسبات RL لازم است منتشر کردهاند - و در مورد سوالات تحقیق بنیادی امروزی بحث میکنند، مانند:
نقش پیشینهها مانند مدلهای پایه، ابرپارامترهای RL و دادههای شروع سرد چیست؟
نقش تولید موازی در مقابل متوالی چیست؟
چگونه محاسبات RL را در حوزههایی که تأیید راهحلها دشوارتر است، مقیاسبندی کنیم؟ - یک ابزار قیمتگذاری غولپیکر LLM که به شما امکان میدهد قیمت مدل را در تقریباً هر ارائهدهندهای مشاهده کنید.
- Dan Shipper یک بررسی با چند نمونه استفاده خلاقانه از o3 انجام داد (همچنین در پست o3 ما پیوند داده شده است).
- این داستان در مورد موسسه آلن تورینگ - چگونه یک موسسه هوش مصنوعی نسازیم توسط Alex Chalmers - نقطه مقابل عالی برای تمام موفقیتهایی است که این روزها در مورد هوش مصنوعی میشنویم.
- Helen Toner - یکی از متفکران مورد علاقه ما در فضای سیاست هوش مصنوعی - یک وبلاگ را شروع کرده است. او چند پست اولیه در مورد کوچک کردن جدول زمانی، تغییر معنای همسویی و عدم تکثیر دارد. تا زمانی که برنامه ارسال ثابت باشد، این در مسیر سریع به توصیههای Interconnects قرار دارد.
- یک پادکست خوب از AI Summer در مورد پروندههایی که قوانین حق نسخهبرداری هوش مصنوعی را طی چند سال آینده تعریف میکنند. این یک موضوع مهم است، اما معمولاً در بین احکام دادگاههای بزرگ نادیده گرفته میشود.
- یک پست جالب در The Alignment Forum در مورد مجموعهای از نتایج منفی برای SAEهایی که در تفسیرپذیری مکانیکی استفاده میشوند، بحث کرد. TLDR:
- برای اعتبارسنجی اینکه آیا SAEها یک تکنیک ارزشمند هستند، بررسی کردیم که آیا آنها در وظیفه پاییندستی تعمیم OOD هنگام تشخیص قصد آسیبرسان در دستورالعملهای کاربر مفید هستند یا خیر.
- نتیجه منفی: SAEها عملکردی ضعیفتر از پروبهای خطی داشتند.
- SpeechMap.ai نرخ امتناع LLMهای مختلف را از طیف گستردهای از موضوعات مورد بحث داغ، مانند دولتها، مذهب یا قومیت، اندازهگیری میکند.
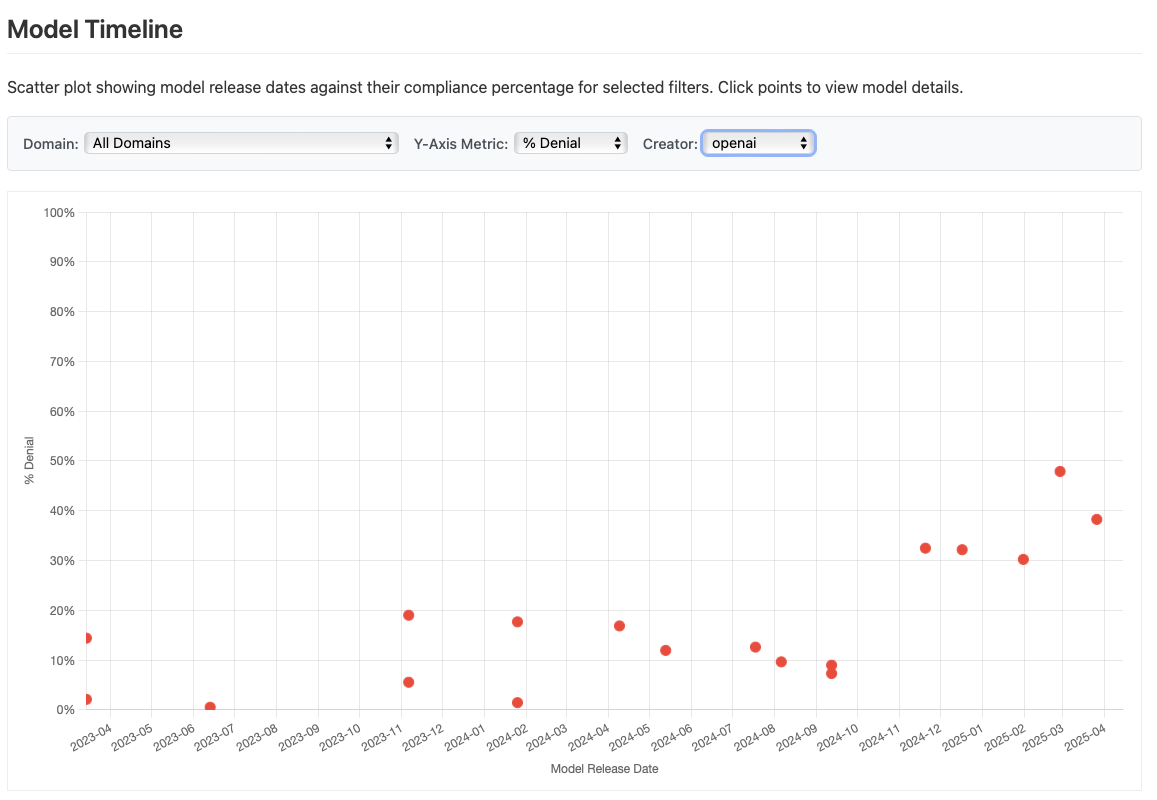
مدلهای جدیدتر OpenAI درخواستهای بیشتری را رد میکنند. منبع: https://speechmap.substack.com/p/speechmapai-is-live - Anthropic چند آموزش برای Claude Code دارد.
استدلال
مدلها
- openhands-lm-32b-v0.1 توسط all-hands: یک نسخه RL تنظیم شده از Qwen2.5 Coder در وظایف عاملیتی برای ویرایش پایگاههای کد. دادهها با استفاده از خود مدل تولید شدهاند - ویرایشهای موفقی که از یک مدل اعمال شدهاند، برای آموزش تکرار بعدی استفاده میشوند.
- Skywork-OR1-Math-7B توسط Skywork: یک مدل استدلال که در چندین مرحله با افزایش طول بافت آموزش داده شده است و عملکرد را در مقایسه با ثابت نگه داشتن طول بافت بهبود میبخشد. پست وبلاگ به جزئیات بیشتری میپردازد، از جمله آزمایشهای آنتروپی آنها از مدل بازیگر.
- cogito-v1-preview-llama-70B توسط deepcogito: یک سری از مدلها با قابلیتهای استدلال اختیاری که با تولید دادههای آموزشی با همان مدل آموزش داده شدهاند، یعنی مدل 70B با دادههای مدل 70B آموزش داده شده است.
- DeepCoder-14B-Preview توسط agentica-org: یک نسخه RL آموزش دیده از نسخه R1 از Qwen2.5 14B. آنها از بینشهای DAPO برای یک نسخه بهبود یافته از GRPO استفاده میکنند که در اینجا پوشش دادیم.
- Kimina-Prover-Preview-Distill-7B توسط AI-MO: یک مدل از Moonshot AI که در اثبات مسائل ریاضی با فرموله کردن آنها در Lean تخصص دارد. آنها همچنین Autoformalizer را منتشر میکنند که قادر به تبدیل زبان طبیعی به کد Lean 4 است. این برای سیستمهایی مانند AlphaProof مفید است.

منبع: https://x.com/JiaLi52524397/status/1911766399971955059 - ZR1-1.5B توسط Zyphra: یک مدل کدنویسی کوچک، که بر اساس نسخه R1 تقطیر شده از Qwen2.5 1.5B با آموزش آن با PRIME ساخته شده است.
مجموعه دادهها
- reasoning-v1-20m توسط glaiveai: یک مجموعه داده استدلال که توسط R1-Distill Llama 70B تولید شده است.
- Multi-subject-RLVR توسط virtuoussy: ترجمه ExamQA چینی به انگلیسی، هر نمونه به یک جفت پرسش و پاسخ آزاد تبدیل شده است.
- OpenCodeReasoning توسط nvidia: 735K راهحل کدنویسی پایتون با ردیابیهای تولید شده توسط R1.
- Llama-Nemotron-Post-Training-Dataset توسط nvidia: دادههای SFT و RL برای آموزش مدلهای Llama-Nemotron.
- DeepMath-103K توسط zwhe99: یک مجموعه داده ریاضی چالش بر انگی.
پیوندها
- یک کتابخانه به سبک nanoGPT خوب، McGill-NLP/nano-aha-moment، برای آموزش LMها با RL از خطوط زمانی ما عبور کرد. ما هنوز آن را آزمایش نکردهایم، اما این نوع تلاشها برای دسترسی به آزمایش کنترل شده روی مدلهای کوچک بسیار تاثیرگذار هستند.