آموزش آگاه از کوانتیزاسیون به آخرین مدلهای گوگل اجازه میدهد تا بر روی پردازندههای گرافیکی محلی و حتی دستگاههای تلفن همراه اجرا شوند.
با یک رویکرد آموزشی تخصصی، این مدلهای جدید Gemma 3 اکنون میتوانند به طور موثر بر روی سختافزار مصرفکننده—مانند پردازندههای گرافیکی مخصوص بازی یا حتی دستگاههای تلفن همراه—اجرا شوند، بدون اینکه کیفیت آنها به طور چشمگیری کاهش یابد. برای درک بهتر، مدلهای اصلی Gemma 3 برای تنظیمات با کارایی بالا با استفاده از NVIDIA H100s و دقت BFloat16 ساخته شدهاند که آنها را عمدتاً از دسترس کاربران عادی دور نگه میدارد.
نکته کلیدی این تغییر، کوانتیزاسیون (Quantization) است، فرآیندی که به طور چشمگیری مصرف حافظه را کاهش میدهد. هر دو مدل و نقاط بازرسی آنها اکنون در Hugging Face و Kaggle در دسترس هستند.
کوانتیزاسیون به معنای ذخیره وزنها و فعالسازیها با بیتهای کمتر است—اغلب ۸، ۴، یا حتی فقط ۲—به جای ۱۶ یا ۳۲ معمول. این منجر به مدلهای کوچکتری میشود که سریعتر اجرا میشوند، زیرا اعداد با دقت پایینتر سریعتر منتقل و پردازش میشوند.
کاهش استفاده از حافظه از طریق آموزش آگاه از کوانتیزاسیون
در Gemma 3، گوگل از آموزش آگاه از کوانتیزاسیون (Quantization-Aware Training - QAT) استفاده میکند، تکنیکی که شرایط دقت کاهشیافته را در طول آموزش معرفی میکند. با شبیهسازی عرض بیت پایینتر از ابتدا، مدل یاد میگیرد که با این محدودیتها سازگار شود و کاهش عملکرد معمول در هنگام اجرا با دقت پایینتر را به حداقل میرساند.
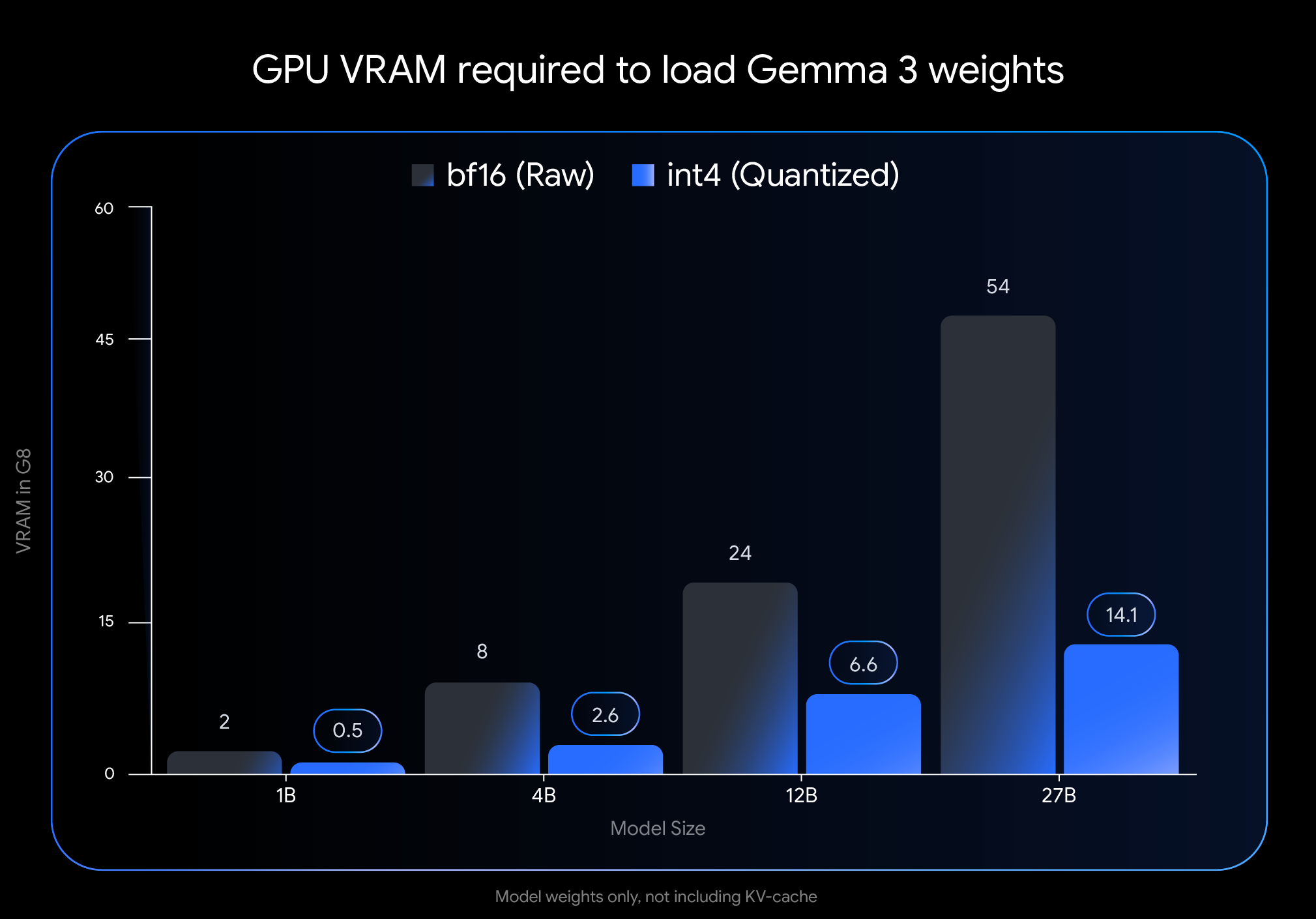
صرفهجویی در حافظه قابل توجه است. به عنوان مثال، مدل 27B از 54 گیگابایت VRAM به تنها 14.1 گیگابایت در فرمت int4 کاهش مییابد. مدل 12B از 24 گیگابایت به 6.6 گیگابایت کاهش مییابد. حتی مدلهای کوچکتر نیز سود میبرند: نسخه 4B با 2.6 گیگابایت ارائه میشود، در حالی که مدل 1B تنها به 0.5 گیگابایت نیاز دارد.
گوگل ادعا میکند که به دلیل QAT، مدلها در برابر کوانتیزاسیون مقاوم هستند، شرایطی که معمولاً منجر به از دست دادن کیفیت مدل میشود. با این حال، این شرکت نتایج معیار بهروز شدهای را برای حمایت از این ادعا منتشر نکرده است.
این مدلها با موتورهای استنتاج رایج برای ادغام در گردش کار موجود سازگار هستند. پشتیبانی بومی برای Ollama، LM Studio و MLX (برای Apple Silicon) در دسترس است. ابزارهایی مانند llama.cpp و gemma.cpp نیز پشتیبانی از مدلهای کوانتیزهشده Gemma را در فرمت GGUF ارائه میدهند.
فراتر از نسخههای رسمی گوگل، جامعه نیز تحت بنر "Gemmaverse" در حال آزمایش است—انواع جامعه که از کوانتیزاسیون پس از آموزش برای ترکیب و تطبیق اندازه مدل، سرعت و کیفیت استفاده میکنند.
خلاصه
- گوگل نسخههای جدیدی از مدلهای زبانی Gemma 3 خود را منتشر کرده است که از کوانتیزاسیون برای کاهش الزامات حافظه استفاده میکنند و به آنها اجازه میدهند تا بر روی پردازندههای گرافیکی مصرفکننده مانند RTX 3090 و حتی بر روی دستگاههای تلفن همراه اجرا شوند.
- با استفاده از آموزش آگاه از کوانتیزاسیون (QAT)، مدلها کیفیت خود را در حالی که از عرض بیت بسیار کوچکتری استفاده میکنند، حفظ میکنند - بزرگترین نسخه هنگام استفاده از فرمت int4 از حدود یک چهارم VRAM اصلی استفاده میکند.
- این مدلهای بهینهشده با موتورهای استنتاج محبوب مانند Ollama، LM Studio و MLX کار میکنند و در فرمتهای مختلف در پلتفرمهایی مانند Hugging Face و Kaggle در دسترس هستند.
منابع: Google Developers