
چرا این موضوع مهم است؟ مایکروسافت BitNet b1.58 2B4T را معرفی کرده است، یک مدل زبانی بزرگ جدید که برای کارایی فوقالعاده طراحی شده است. برخلاف مدلهای هوش مصنوعی معمولی که برای نمایش هر وزن به اعداد ممیز شناور 16 یا 32 بیتی متکی هستند، BitNet فقط از سه مقدار مجزا استفاده میکند: 1-، 0 یا 1+. این رویکرد، که به عنوان کوانتیزاسیون سهتایی (ternary quantization) شناخته میشود، به هر وزن اجازه میدهد تا فقط در 1.58 بیت ذخیره شود. نتیجه یک مدلی است که به طور چشمگیری مصرف حافظه را کاهش میدهد و میتواند بسیار آسانتر بر روی سختافزار استاندارد اجرا شود، بدون نیاز به GPUهای پیشرفته که معمولاً برای هوش مصنوعی در مقیاس بزرگ مورد نیاز است.
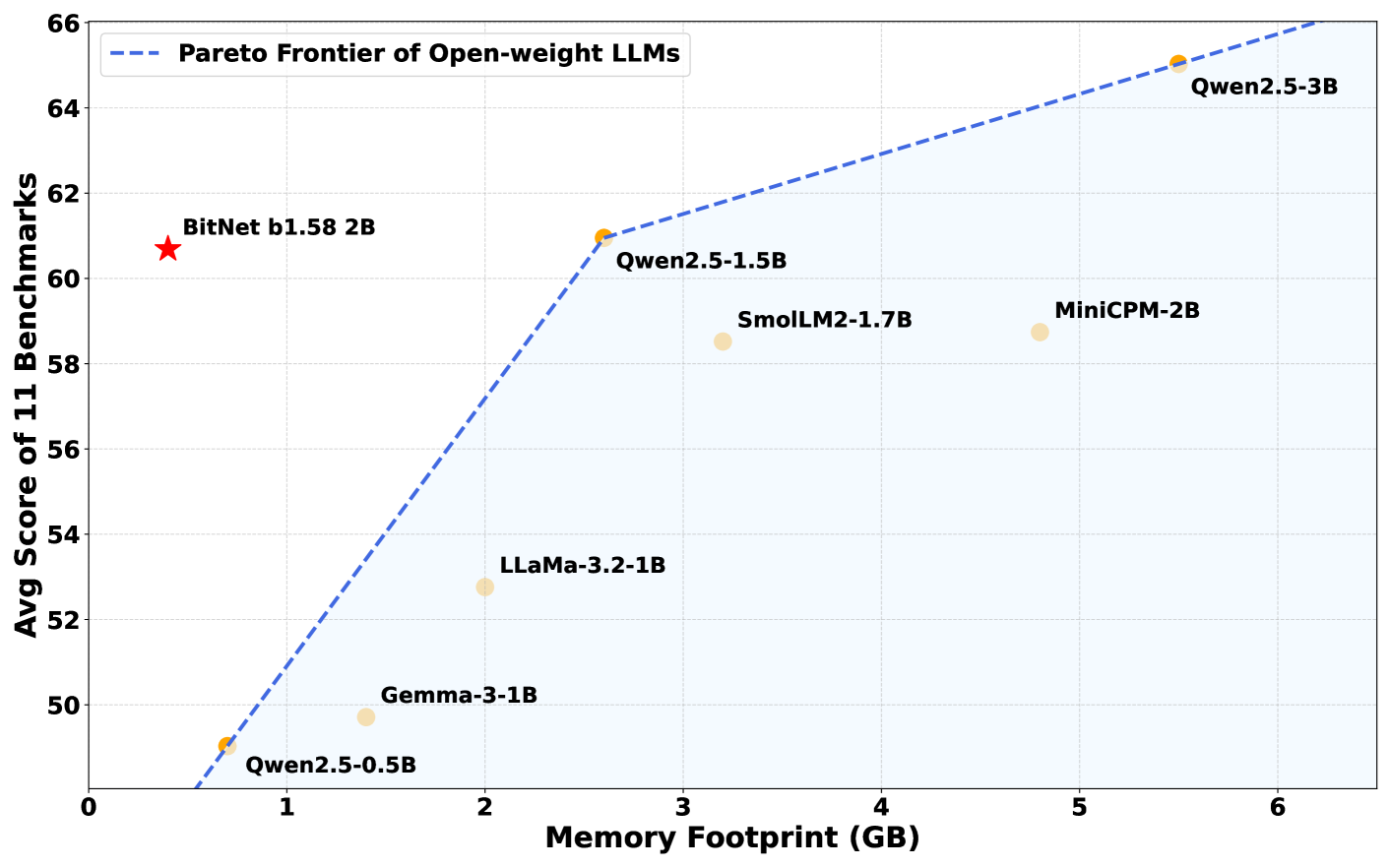
مدل BitNet b1.58 2B4T توسط گروه هوش مصنوعی عمومی مایکروسافت توسعه یافته و شامل دو میلیارد پارامتر است - مقادیر داخلی که مدل را قادر میسازد زبان را درک و تولید کند. برای جبران وزنهای کم دقت خود، مدل بر روی یک مجموعه داده عظیم از چهار تریلیون توکن آموزش داده شده است، تقریباً معادل محتویات 33 میلیون کتاب. این آموزش گسترده به BitNet اجازه میدهد تا در حد - یا در برخی موارد، بهتر از - سایر مدلهای پیشرو با اندازه مشابه، مانند Llama 3.2 1B متا، Gemma 3 1B گوگل و Qwen 2.5 1.5B علیبابا عمل کند.
در تستهای معیار، BitNet b1.58 2B4T عملکرد قوی در طیف وسیعی از وظایف، از جمله مسائل ریاضی مدرسه و سوالات نیازمند استدلال عقل سلیم از خود نشان داد. در برخی ارزیابیها، حتی از رقبای خود نیز بهتر عمل کرد.
چیزی که واقعاً BitNet را متمایز میکند، کارایی حافظه آن است. این مدل فقط به 400 مگابایت حافظه نیاز دارد، کمتر از یک سوم آنچه که مدلهای قابل مقایسه معمولاً نیاز دارند. در نتیجه، میتواند به آرامی بر روی پردازندههای استاندارد، از جمله تراشه M2 اپل، بدون تکیه بر GPUهای پیشرفته یا سختافزار تخصصی هوش مصنوعی اجرا شود.
این سطح از کارایی توسط یک چارچوب نرمافزاری سفارشی به نام bitnet.cpp امکانپذیر شده است که برای استفاده کامل از وزنهای سهتایی مدل بهینه شده است. این چارچوب عملکرد سریع و سبک را بر روی دستگاههای محاسباتی روزمره تضمین میکند.
کتابخانههای استاندارد هوش مصنوعی مانند Transformers Hugging Face همان مزایای عملکردی BitNet b1.58 2B4T را ارائه نمیدهند، و استفاده از چارچوب bitnet.cpp سفارشی را ضروری میسازد. چارچوب موجود در GitHub در حال حاضر برای پردازندهها بهینه شده است، اما پشتیبانی از سایر انواع پردازنده در بهروزرسانیهای آینده برنامهریزی شده است.
ایده کاهش دقت مدل برای صرفهجویی در حافظه جدید نیست، زیرا محققان مدتهاست به بررسی فشردهسازی مدل پرداختهاند. با این حال، بیشتر تلاشهای گذشته شامل تبدیل مدلهای با دقت کامل پس از آموزش بود، که اغلب به قیمت از دست دادن دقت تمام میشد. BitNet b1.58 2B4T رویکرد متفاوتی را در پیش میگیرد: از ابتدا فقط با استفاده از سه مقدار وزن (1-، 0 و 1+) آموزش داده میشود. این به آن اجازه میدهد تا از بسیاری از تلفات عملکردی که در روشهای قبلی مشاهده شده است، جلوگیری کند.
این تغییر پیامدهای مهمی دارد. اجرای مدلهای بزرگ هوش مصنوعی معمولاً به سختافزار قدرتمند و انرژی قابل توجهی نیاز دارد، عواملی که هزینهها و تأثیرات زیستمحیطی را افزایش میدهند. از آنجایی که BitNet به محاسبات بسیار ساده متکی است - بیشتر جمع به جای ضرب - انرژی بسیار کمتری مصرف میکند.
محققان مایکروسافت تخمین میزنند که 85 تا 96 درصد انرژی کمتری نسبت به مدلهای با دقت کامل قابل مقایسه مصرف میکند. این میتواند راه را برای اجرای هوش مصنوعی پیشرفته به طور مستقیم بر روی دستگاههای شخصی، بدون نیاز به ابررایانههای مبتنی بر ابر، باز کند.
با این حال، BitNet b1.58 2B4T دارای برخی محدودیتها است. در حال حاضر فقط از سختافزار خاصی پشتیبانی میکند و به چارچوب bitnet.cpp سفارشی نیاز دارد. پنجره متنی آن - مقدار متنی که میتواند به طور همزمان پردازش کند - کوچکتر از پیشرفتهترین مدلها است.
محققان هنوز در حال بررسی این موضوع هستند که چرا این مدل با چنین معماری سادهای عملکرد خوبی دارد. هدف از کارهای آینده گسترش قابلیتهای آن، از جمله پشتیبانی از زبانهای بیشتر و ورودیهای متنی طولانیتر است.