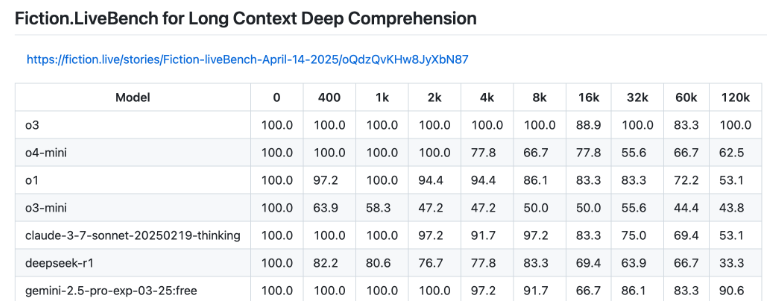
یکی از نتایج قانع کننده در محک زنی های اخیر o3، عملکرد آن در وظایف متن طولانی است.
o3 با پشتیبانی از حداکثر 200000 توکن، اولین مدلی است که به امتیاز کامل 100 درصد در محک Fiction.live با استفاده از 128000 توکن دست یافته است - که تقریباً 96000 کلمه است. برای هر مدل زبانی که با روایتهای گسترده یا اسناد عظیم کار میکند، این یک جهش چشمگیر به جلو است. تنها مدلی که نزدیک به این است Gemini 2.5 Pro گوگل است که امتیاز 90.6 درصد را کسب کرده است، در حالی که o3-mini و o4-mini بسیار عقبتر هستند.
تست Fiction.LiveBench برای این طراحی شده است که ببیند مدلها چقدر میتوانند به طور کامل داستانهای پیچیده و زمینههای آنها را درک کرده و به طور دقیق بازتولید کنند، حتی زمانی که متن به طولانیترین حد خود میرسد.
به عنوان مثال، Llama 4 متا، یک پنجره زمینه تا ده میلیون توکن را تبلیغ میکند - عددی که روی کاغذ چشمگیر به نظر میرسد. اما در عمل، برای چیزی فراتر از جستجوهای ساده کلمات به سختی مفید است و در درک معنادار طولانیمدت کوتاهی میکند.
این فقط Llama 4 نیست. در کل، بسیاری از مدلها در درک واقعی متن طولانی عملکرد ضعیفی دارند و این پنجرههای زمینه عظیم را بیشتر به یک حقه بازاریابی تبدیل میکنند تا یک قابلیت واقعی. در بدترین حالت، آنها به کاربران این تصور را میدهند که مدل کل سند را هضم میکند، در حالی که در واقع، بخش زیادی از متن تا حد زیادی مورد توجه قرار نمیگیرد - نقصانی که توسط مطالعات متعدد برجسته شده است.
برای هر کسی که نیازهای واقعی دارد که به عملکرد عمیق و مداوم در ورودیهای عظیم نیاز دارد، o3 اکنون استاندارد واضحی است.
منابع: Fiction.liveBench