"درس تلخ" ریچارد اس. ساتن یک حقیقت سخت را در قلب هوش مصنوعی مدرن بیان میکند: نه تزریق هوشمندانه دانش انسانی، بلکه الگوریتمهای یادگیری و جستجوی مقیاسپذیر هستند که پیشرفتهای ماندگار را ارائه میدهند. اکنون، مقاله جدیدی از ساتن و دیوید سیلور بر اساس این تز بنا شده است و دیدگاهی گسترده برای عوامل هوش مصنوعی ترسیم میکند که صرفاً از طریق عمل و بازخورد پیشرفت میکنند.
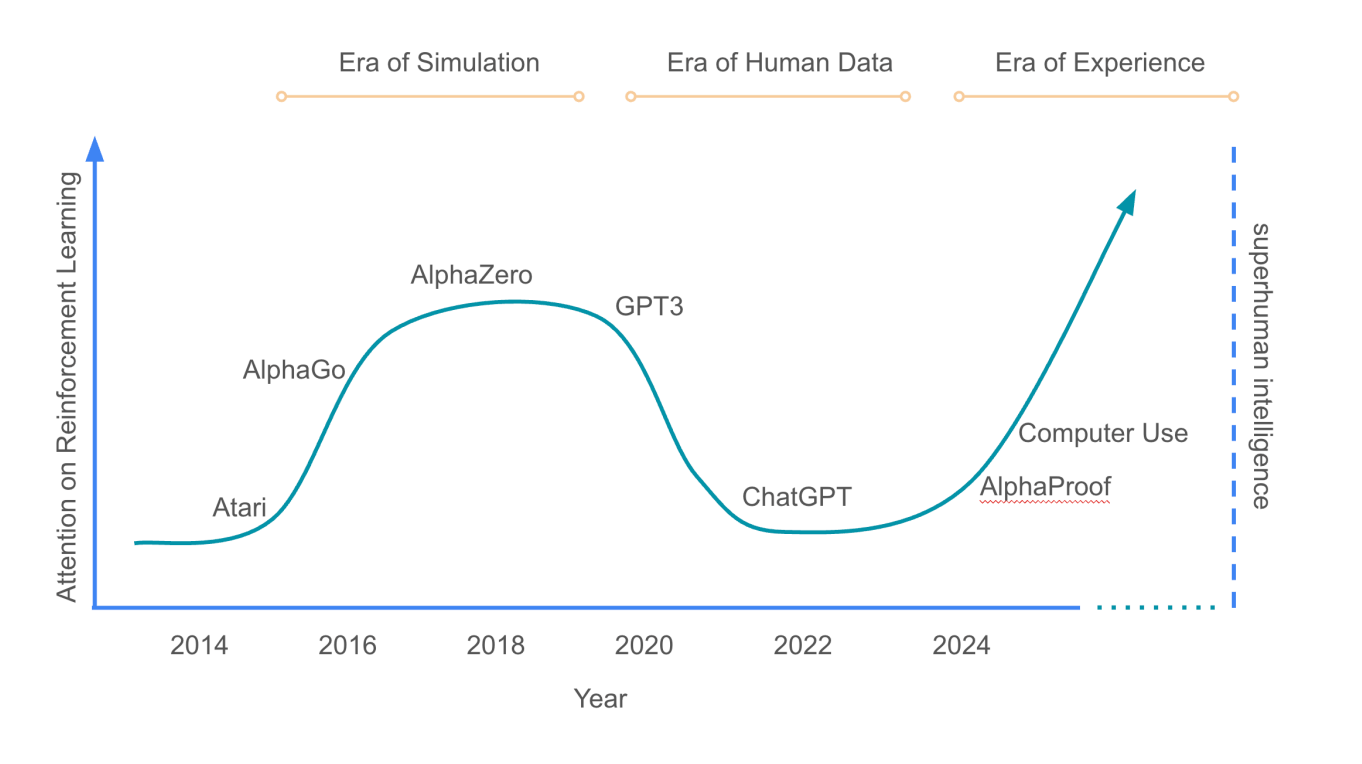
در سال 2019، ساتن مقالهای مختصر منتشر کرد که به یکی از نقاط عطف تأثیرگذار در تحقیقات فعلی هوش مصنوعی تبدیل شده است. استدلال اصلی او: بزرگترین جهشها در هوش مصنوعی از بینش انسانی ناشی نشدهاند، بلکه از ماشینهایی ناشی شدهاند که با محاسبات عظیم و حداقل دانش داخلی، یاد میگیرند که خودشان را بهبود بخشند.
ساتن استدلال میکند که انسانها تمایل دارند شهود خود را به الگوریتمها تحمیل کنند، اما در نهایت، رویکردهای سیستماتیک و دادهمحور هستند که برنده میشوند. این "درس تلخ" اکنون در یادگیری تقویتی (Reinforcement Learning یا RL) اساسی است، فناوری پشت AlphaGo و اخیراً موج جدیدی از مدلهای زبانی "استدلالی".
پنج سال بعد، ساتن (برنده جایزه تورینگ و رئیس آزمایشگاه آلبرتا دیپمایند)، به همراه دانشجوی دکترای سابق خود و رهبر RL دیپمایند، دیوید سیلور، مقاله جدیدی منتشر کردهاند: "به عصر تجربه خوش آمدید."
این مقاله خواستار یک تغییر اساسی است: از ساختن هوش مصنوعی بر اساس دانش انسانی به ساختن سیستمهایی که با عمل در جهان و یادگیری از بازخورد بهبود مییابند. این دیدگاه: هوش مصنوعی که بر اساس شرایط خود تکامل مییابد، نه فقط با بازسازی آنچه مردم از قبل میدانند.
فراتر رفتن از دادههای تولید شده توسط انسان
ساتن و سیلور اشاره میکنند که هوش مصنوعی مولد امروزی (مانند مدلهای زبانی بزرگ) تقریباً به طور کامل بر روی دادههای انسانی ساخته شدهاند: کتابها، وبسایتها، انجمنها، همگی خراشیده و دوباره بستهبندی شدهاند. این مدلها میتوانند کارهای زیادی انجام دهند، اما یک سقف وجود دارد: صنعت در نهایت از دادههای انسانی با کیفیت بالا تهی میشود، و برخی از پیشرفتها به سادگی فراتر از آن چیزی هستند که انسانها تاکنون فهمیدهاند. هوش مصنوعی که با تقلید یاد میگیرد، شایسته خواهد شد، اما واقعاً خلاق نخواهد بود.
استدلال آنها این است که ما به عواملی نیاز داریم که همیشه در حال یادگیری و انطباق باشند. هوش مصنوعی آینده به جای اینکه یک بار آموزش ببیند و سپس ثابت بماند، باید در یک جریان بیپایان از تجربیات زندگی کند و در طول ماهها یا سالها با محیط خود سازگار شود، درست مانند انسانها یا حیوانات. هر عمل جدید، هر آزمایش، منبع جدیدی از داده است. برخلاف متن نوشته شده توسط انسان، تجربه بی حد و حصر است.
آنها این را به عنوان یک تغییر اساسی چارچوببندی میکنند: از مجموعههای داده ثابت به تعامل مداوم، از یادگیری نظارت شده به کاوش باز. در این چارچوب، هوش از طریق رفتار و انطباق پدیدار میشود، نه از طریق اعلانها یا مجموعههای داده. در صورت موفقیت، این رویکرد میتواند منجر به پیشرفتهای چشمگیری در قابلیتهای هوش مصنوعی شود.
آموزش هوش مصنوعی با مدلهای جهانی
این مقاله شرح میدهد که چگونه روشهای کلاسیک RL را میتوان با تکنیکهای جدیدتر ترکیب کرد. یک مثال AlphaProof است، یک سیستم DeepMind که برای ریاضیات رسمی طراحی شده است. این سیستم یک مدل زبانی از پیش آموزش دیده را با الگوریتم یادگیری تقویتی AlphaZero ادغام میکند. پس از یادگیری مختصر از اثباتهای انسانی، AlphaProof توانست بیش از 100 میلیون مرحله اثبات اضافی را از طریق کاوش مستقل ایجاد کند و از سیستمهای آموزش دیده صرفاً بر روی دادههای انسانی انتخاب شده بهتر عمل کند.
ساتن و سیلور میخواهند این را به دنیای واقعی گسترش دهند: آنها دستیاران بهداشتی را توصیف میکنند که الگوهای خواب را تجزیه و تحلیل میکنند و توصیهها را تنظیم میکنند، یا عوامل آموزشی که پیشرفت سالهای دانشآموز را ردیابی میکنند، یا حتی هوش مصنوعی علمی که آزمایشهای خود را انجام میدهند.
نکته کلیدی این است که این عوامل نه تنها از رتبهبندیهای انسانی، بلکه از سیگنالهای قابل اندازهگیری در محیط بازخورد میگیرند: ضربان قلب در حالت استراحت، سطح CO2، نتایج آزمایش. بازخورد انسانی هنوز میتواند نقش داشته باشد، اما فقط اگر بر اساس پیامدهای یک عمل باشد، مانند طعم یک کیک یا احساس شما بعد از یک تمرین.
وقتی صحبت از "تفکر" ماشینی میشود، نویسندگان استدلال میکنند که باید از رویههای فعلی جدا شویم. مدلهای زبانی سعی میکنند استدلال انسانی را از طریق چیزهایی مانند اعلانهای زنجیرهای تقلید کنند، اما این فقط اشتباهات و تعصبات انسانی را در خود جای میدهد.
در عوض، عوامل باید "مدلهای جهانی" داخلی خود را بسازند، شبیهسازیهایی که از آنها برای پیشبینی نتایج اقدامات خود استفاده میکنند. این امر برنامهریزی واقعی را ممکن میکند، نه فقط ترفندهای زبانی هوشمندانه. آنها عوامل آینده را در حال حرکت از طریق مراحل میانی میبینند: فراخوانی APIها، اجرای کد و مشاهده بازخورد، همه به عنوان داربست به سوی خودمختاری واقعی.
آنها همچنین این "عصر تجربه" را به عنوان بازگشت به ریشههای RL میبینند که تحت الشعاع موفقیت مدلهای زبانی بزرگ و RLHF قرار گرفتهاند. یادگیری و برنامهریزی بلندمدت به ابزارهایی مانند انتزاع زمانی، رفتار اکتشافی و توابع ارزش پویا نیاز دارد که همگی قلمرو کلاسیک RL هستند.
نویسندگان استدلال میکنند که این تغییر در حال حاضر در جریان است. نمونهها عبارتند از عوامل دیجیتالی که با رابطهای کاربری تعامل دارند، سیستمهای RL که وظایف باز را انجام میدهند، و سیستمهای هوش مصنوعی که به طور فزایندهای به جریانهای داده دنیای واقعی متصل میشوند. یکی از این سیستمهای عامل، مدل o3 مورد استفاده برای تحقیقات عمیق OpenAI، با استفاده از تکنیکهای یادگیری تقویتی بر روی "طیف گستردهای از چالشهای پیچیده مرور و استدلال" آموزش داده شد.
خودمختاری بیشتر به معنای مسئولیت بیشتر است
با خودمختاری بیشتر، هم فرصت و هم خطر به وجود میآید. عواملی که قادر به برنامهریزی و انطباق بلندمدت هستند، میتوانند مهارتهایی را کسب کنند که به طور سنتی منحصر به فرد انسان تلقی میشوند. این میتواند به این معنی باشد که کنترل و تنظیم چنین سیستمهایی دشوارتر از نرمافزار معمولی خواهد بود.
اما ساتن و سیلور پیشنهاد میکنند که ماهیت تعامل مداوم ممکن است ایمنی را بهبود بخشد. عواملی که در محیطهای دنیای واقعی تعبیه شدهاند، میتوانند یاد بگیرند که عواقب ناخواسته را تشخیص دهند و بر اساس آن تنظیم شوند. توابع پاداش میتوانند از طریق بازخورد کاربر اصلاح شوند. و محدودیتهای دنیای واقعی، مانند مطالعات پزشکی، به طور طبیعی پیشرفت بیپروا را کند میکنند.
ساتن و سیلور خاطرنشان میکنند که ما در حال حاضر مواد فنی لازم را داریم: محاسبات کافی، محیطهای شبیهسازی و الگوریتمهای RL. در حالی که "هوش تجربی" هنوز یک زمینه جوان است، ابزارها در دسترس هستند، و محققان خواستار تمایل جامعه هوش مصنوعی برای انطباق با یک الگوی جدید هستند.
برداشت آنها صریح است: تجربه نباید به عنوان یک فکر بعدی تلقی شود، بلکه باید به عنوان پایه و اساس تمام توسعه هوش مصنوعی عمل کند. ساتن و سیلور استدلال میکنند که پیشرفتهای آینده از سیستمهایی ناشی میشود که یاد میگیرند مستقل فکر کنند، نه اینکه صرفاً ایدههای انسانی را تکرار کنند.
برای اطلاعات بیشتر در مورد این موضوع، سیلور ایدههای این مقاله را در پادکست Google DeepMind توضیح میدهد.
تشخیص محدودیتهای مدلهای زبانی
این ایده که مدلسازی زبانی محض ما را به هوش مصنوعی فوق بشری نمیرساند، بیسروصدا در این صنعت به جریان اصلی تبدیل شده است. مهم نیست که چه مقدار متن برای آموزش استفاده میشود، مدلها همچنان با حسCommon Sense (فهم عامیانه) و توانایی تعمیم در وظایف دست و پنجه نرم میکنند.
صداهای پیشرو در این مسیر حرکت میکنند. ایلیا سوتسکور، بنیانگذار و دانشمند ارشد سابق OpenAI، اکنون در حال کار بر روی مسیرهای جایگزین به سوی هوش فوقالعاده در استارتآپ جدید خود "SSI" است. سوتسکور قبلاً در سال 2024 در مورد رسیدن به "اوج داده" صحبت میکرد و خواستار رویکردهای جدید شد. یان لکان از متا در حال فشار برای معماریهای جدید فراتر از مدلهای زبانی است، و سم آلتمن (مدیرعامل OpenAI) در سال 2023 گفت که زبان به تنهایی برای AGI و فراتر از آن کافی نیست.
یکی از مسیرهای امیدوارکننده مفهوم "مدل جهانی" ذکر شده در بالا است، سیستمهایی که میتوانند نه تنها زبان، بلکه تجربیات حسی و حرکتی را نیز پردازش کنند و حس علیت، فضا، زمان و عمل را ایجاد کنند. نکته اصلی: پیشرفتهای بزرگ در اینجا هنوز غیرقابل دسترس هستند.
شاید بزرگترین چالش برای RL خارج از حوزههای خاص مانند یک بازی تختهای یا وظایف ریاضی خاص، تعمیم باشد، به ویژه برای مشکلاتی که پاسخ درست یا غلط مشخصی ندارند. جدیدترین LLMهای استدلالی در ریاضیات بسیار قویتر از مدلهای سنتی هستند، اما لزوماً در وظایف دانش یا خلاقیت بهتر عمل نمیکنند.