
Together AI ابزار Open Deep Research را معرفی کرده است، یک ابزار متنباز که برای پاسخ به سوالات پیچیده از طریق تحقیقات ساختاریافته و چند مرحلهای وب طراحی شده است.
این چارچوب بر اساس مفهومی است که در اصل توسط OpenAI معرفی شد، اما رویکردی شفافتر دارد: کد، مجموعهدادهها و معماری سیستم آن به طور کامل برای عموم باز است.
برخلاف موتورهای جستجوی معمولی که فهرستی از پیوندها را برمیگردانند و کاربران را ملزم به استخراج اطلاعات مرتبط میکنند، Open Deep Research گزارشهای ساختاریافته با ارجاعات ایجاد میکند. به گفته Together AI، این سیستم "برای ارائه گزارشهای ساختاریافته با ارجاعات طراحی شده است"، همانطور که در یک پست وبلاگ شرکت توضیح داده شده است.
شرکتهای دیگری نیز ابزارهای مشابهی را راهاندازی کردهاند. گوگل، Grok و Perplexity همگی قابلیتهای سبک تحقیقات عمیق را ارائه میدهند. Anthropic به تازگی یک ویژگی تحقیقات مبتنی بر عامل را برای مدل Claude خود معرفی کرده است. اندکی پس از انتشار سیستم OpenAI، Hugging Face جایگزین متنباز خود را اعلام کرد اما توسعه را ادامه نداده است.
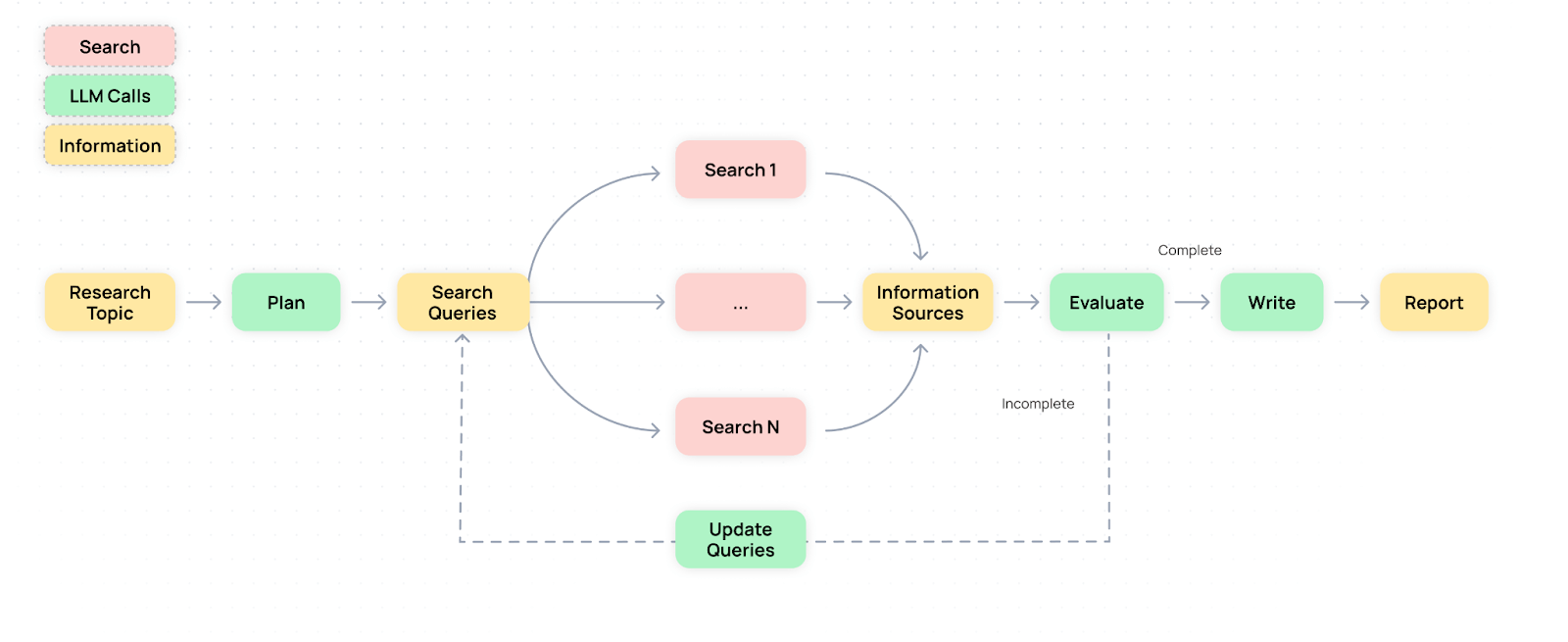
برنامهریزی، جستجو، بازتاب، نوشتن
Open Deep Research از یک فرآیند چهار مرحلهای استفاده میکند. یک مدل برنامهریزی ابتدا فهرستی از پرس و جوهای مرتبط ایجاد میکند، که سپس برای جمعآوری محتوا از طریق API جستجوی Tavily استفاده میشود. یک مدل تأیید، شکافهای دانش را بررسی میکند و سپس یک مدل نوشتن، گزارش نهایی را گردآوری میکند.
برای رسیدگی به اسناد طولانی، یک مدل خلاصهسازی اضافی، محتوا را متراکم میکند و ارتباط آن را ارزیابی میکند. هدف از این مرحله جلوگیری از فراتر رفتن مدلهای زبانی بزرگ (Large Language Models) از محدودیتهای پنجره متن آنها است.
معماری سیستم شامل مدلهای تخصصی از Alibaba، Meta و DeepSeek است. Qwen2.5-72B مرحله برنامهریزی را مدیریت میکند، در حالی که Llama-3.3-70B محتوا را خلاصه میکند. Llama-3.1-70B دادههای ساختاریافته را استخراج میکند و DeepSeek-V3 گزارش نهایی را مینویسد. تمام مؤلفهها در زیرساخت ابری خصوصی Together AI میزبانی میشوند.
خروجیهای چندوجهی و قابلیت پادکست
خروجیهای نهایی در HTML قالببندی شده و شامل عناصر متنی و بصری هستند. این سیستم از کتابخانه جاوا اسکریپت Mermaid JS برای تولید نمودارها استفاده میکند و تصاویر جلد خودکار را با استفاده از مدلهای Flux از Black Forest Labs ایجاد میکند.
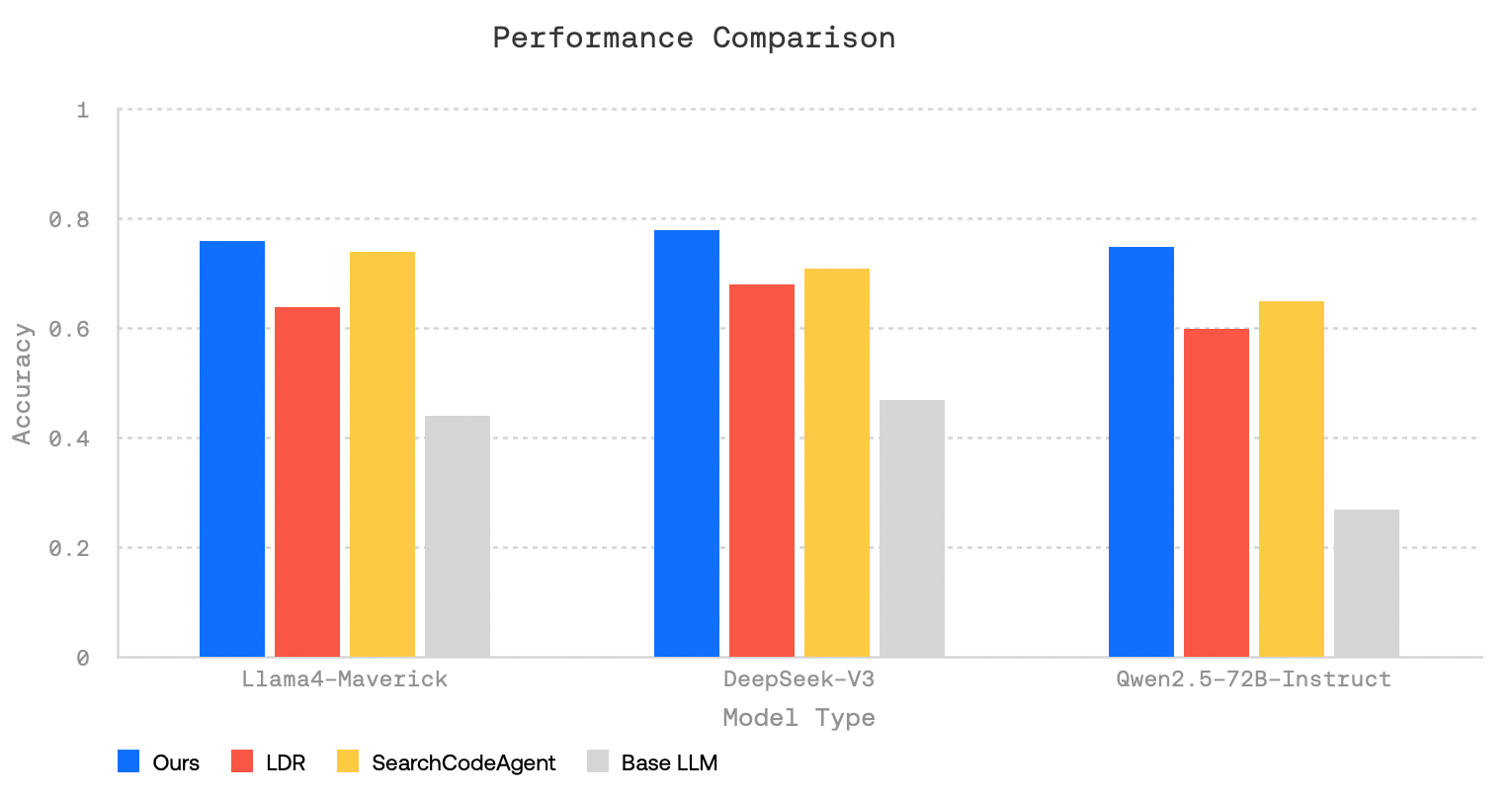
معیارهای محک، مزایای بازیابی چند مرحلهای را نشان میدهند
عملکرد با استفاده از سه معیار محک ارزیابی شد: FRAMES (استدلال چند مرحلهای)، SimpleQA (دانش واقعی) و HotPotQA (سوالات چند هسته ای). در هر سه مورد، Open Deep Research از مدلهای پایه که از ابزارهای جستجو استفاده نمیکنند، عملکرد بهتری داشت. این سیستم همچنین کیفیت پاسخ بالاتری نسبت به Open Deep Research (LDR) لانگچین و SmolAgents (SearchCodeAgent) هاگینگ فیس نشان داد.
بر اساس نتایج آزمایش، دورهای متعدد تحقیق به طور قابل توجهی دقت را بهبود بخشید. هنگامی که سیستم به یک تکرار جستجو محدود شد، عملکرد کاهش یافت.
محدودیتهای شناخته شده: توهمات، سوگیری، دادههای قدیمی
علیرغم پیشرفتها، برخی از ضعفهای اساسی همچنان باقی مانده است. همانطور که Together AI اشاره میکند، "خطاها در مراحل اولیه میتوانند از طریق خط لوله منتشر شوند." این سیستم همچنین در معرض توهمات است، به ویژه هنگام تفسیر منابع مبهم یا متناقض.
سوگیری ساختاری در دادههای آموزشی یا شاخصهای جستجو نیز ممکن است بر نتایج تأثیر بگذارد. موضوعاتی که پوشش محدودی دارند یا نیاز به اطلاعات بلادرنگ دارند—مانند رویدادهای زنده—به ویژه آسیبپذیر هستند. در حالی که ذخیرهسازی میتواند هزینهها را کاهش دهد، Together AI هشدار میدهد که اگر سیاست انقضا تعیین نشود، میتواند منجر به ارائه اطلاعات قدیمی شود.
پلتفرم باز برای تحقیق و توسعه
Together AI میگوید این انتشار به منظور ایجاد یک پایه باز برای آزمایش و بهبود بیشتر است. این معماری به گونهای طراحی شده است که مدولار و قابل توسعه باشد و به توسعهدهندگان اجازه میدهد مدلهای خود را ادغام کنند، منابع داده را سفارشی کنند یا فرمتهای خروجی جدید اضافه کنند. تمام کدها و مستندات به صورت عمومی از طریق GitHub در دسترس هستند.
این شرکت قبلاً یک مدل کد متنباز را منتشر کرد که به سطح عملکرد o3-mini OpenAI نزدیک میشود، اما با پارامترهای بسیار کمتر.