
مهندسی ویژگی همچنان یکی از مؤثرترین راهها برای بهبود دقت مدل هنگام کار با دادههای جدولی است. برخلاف حوزههایی مانند پردازش زبان طبیعی (NLP) و بینایی کامپیوتر، که در آن شبکههای عصبی میتوانند الگوهای غنی را از ورودیهای خام استخراج کنند، بهترین مدلهای جدولی - بهویژه درختهای تصمیم تقویتشده با گرادیان - همچنان از ویژگیهای خوشساخت مزیت قابل توجهی به دست میآورند. با این حال، تعداد بالقوه بسیار زیاد ویژگیهای مفید به این معنی است که بررسی کامل آنها اغلب از نظر محاسباتی بسیار پرهزینه است. تلاش برای تولید و اعتبارسنجی صدها یا هزاران ایده ویژگی با استفاده از pandas استاندارد روی یک CPU به سادگی بسیار کند است و عملاً غیرممکن است.
اینجاست که شتابدهی GPU بازی را تغییر میدهد. با استفاده از NVIDIA cuDF-pandas، که عملیات pandas را بر روی GPU ها با صفر تغییر کد سرعت میبخشد، به من این امکان را داد تا به سرعت بیش از 10000 ویژگی مهندسیشده را برای مسابقه زمین بازی فوریه Kaggle تولید و آزمایش کنم. این فرآیند کشف تسریعشده عامل تمایز کلیدی بود. در یک بازه زمانی به شدت کاهش یافته - روزها به جای ماههای بالقوه - 500 ویژگی برتر کشفشده به طور قابل توجهی دقت مدل XGBoost من را افزایش داد و مقام اول را در مسابقه پیشبینی قیمت کولهپشتی تضمین کرد. در زیر، من تکنیکهای اصلی مهندسی ویژگی را که با cuDF-pandas تسریع شدهاند، به اشتراک میگذارم که منجر به این نتیجه شد.
Groupby(COL1)[COL2].agg(STAT)
قدرتمندترین تکنیک مهندسی ویژگی، تجمیعهای Groupby است. به طور مشخص، ما کد groupby(COL1)[COL2].agg(STAT) را اجرا میکنیم. اینجاست که ما بر اساس ستون COL1 گروهبندی میکنیم و یک آماره STAT را روی ستون دیگری COL2 جمعآوری (یعنی محاسبه) میکنیم. ما از سرعت NVIDIA cuDF-Pandas برای بررسی هزاران ترکیب COL1، COL2، STAT استفاده میکنیم. ما آمارههایی (STAT) مانند "میانگین"، "std"، "تعداد"، "حداقل"، "حداکثر"، "تعداد منحصربهفرد"، "Skew" و غیره را امتحان میکنیم. ما COL1 و COL2 را از ستونهای موجود دادههای جدولی خود انتخاب میکنیم. هنگامی که COL2 ستون هدف است، از اعتبارسنجی متقابل تودرتو برای جلوگیری از نشت در محاسبات اعتبارسنجی خود استفاده میکنیم. وقتی COL2 هدف است، این عملیات رمزگذاری هدف نامیده میشود.
Groupby(COL1)['Price'].agg(HISTOGRAM BINS)
وقتی groupby(COL1)[COL2] را انجام میدهیم، یک توزیع (مجموعه) از اعداد برای هر گروه داریم. به جای محاسبه یک آماره واحد (و ایجاد یک ستون جدید)، میتوانیم هر مجموعه از اعدادی را که این توزیع اعداد را توصیف میکنند محاسبه کنیم و ستونهای جدید زیادی را با هم ایجاد کنیم.
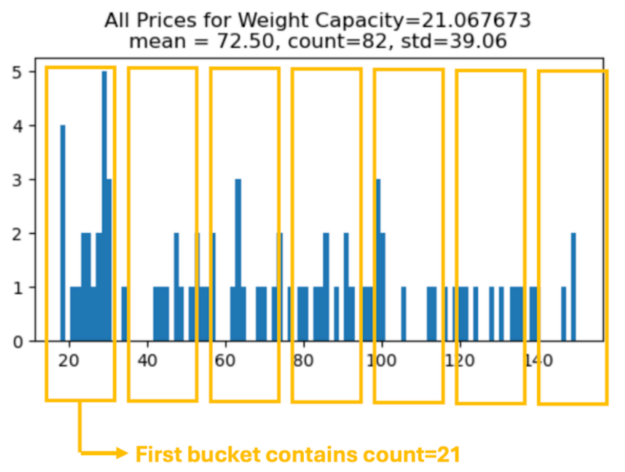
در زیر یک هیستوگرام برای گروه Weight Capacity = 21.067673 نمایش میدهیم. میتوانیم تعداد عناصر موجود در هر سطل (با فاصله مساوی) را شمارش کنیم و یک ویژگی مهندسیشده جدید برای هر شمارش سطل ایجاد کنیم تا به عملیات groupby بازگردیم! در زیر هفت سطل نمایش میدهیم، اما میتوانیم تعداد سطلها را به عنوان یک ابرپارامتر در نظر بگیریم.
result = X_train2.groupby("WC")["Price"].apply(make_histogram)
X_valid2 = X_valid2.merge(result, on="WC", how="left")
Groupby(COL1)['Price'].agg(QUANTILES)
ما میتوانیم groupby کنیم و چندکها را برای QUANTILES = [5,10,40,45,55,60,90,95] محاسبه کنیم و هشت مقدار را برای ایجاد هشت ستون جدید برگردانیم.
for k in QUANTILES:
result = X_train2.groupby('Weight Capacity (kg)').\
agg({'Price': lambda x: x.quantile(k/100)})
همه مقادیر NAN به عنوان یک ستون پایه-2 تکی
ما میتوانیم یک ستون جدید از همه مقادیر NAN در چندین ستون ایجاد کنیم. این یک ستون قدرتمند است که میتوانیم متعاقباً از آن برای تجمیعهای groupby یا ترکیب با ستونهای دیگر استفاده کنیم.
train["NaNs"] = np.float32(0)
for i,c in enumerate(CATS):
train["NaNs"] += train[c].isna()*2**i
قرار دادن ستون عددی در سطلها
قدرتمندترین (پیشبینیکنندهترین) ستون در این مسابقه ظرفیت وزن است. ما میتوانیم ستونهای قدرتمندتری را بر اساس این ستون با سطلبندی این ستون با گرد کردن ایجاد کنیم.
for k in range(7,10):
n = f"round{k}"
train[n] = train["Weight Capacity (kg)"].round(k)
استخراج Float32 به عنوان رقم
قدرتمندترین (پیشبینیکنندهترین) ستون در این مسابقه ظرفیت وزن است. ما میتوانیم ستونهای قدرتمندتری را بر اساس این ستون با استخراج ارقام ایجاد کنیم. این تکنیک عجیب به نظر میرسد، اما اغلب برای استخراج اطلاعات از یک شناسه محصول استفاده میشود که در آن ارقام فردی در یک شناسه محصول اطلاعاتی در مورد یک محصول مانند برند، رنگ و غیره را منتقل میکنند.
for k in range(1,10):
train[f'digit{k}'] = ((train['Weight Capacity (kg)'] * 10**k) % 10).fillna(-1).astype("int8")
ترکیب ستونهای دستهبندی
هشت ستون دستهبندی در این مجموعه داده وجود دارد (به استثنای ستون عددی ظرفیت وزن). ما میتوانیم با ترکیب تمام ترکیبهای ستونهای دستهبندی، 28 ستون دستهبندی دیگر ایجاد کنیم. ابتدا، ستون دستهبندی اصلی را با عدد صحیح با -1 به عنوان NAN برچسبگذاری میکنیم. سپس اعداد صحیح را ترکیب میکنیم:
for i,c1 in enumerate(CATS[:-1]):
for j,c2 in enumerate(CATS[i+1:]):
n = f"{c1}_{c2}"
m1 = train[c1].max()+1
m2 = train[c2].max()+1
train[n] = ((train[c1]+1 + (train[c2]+1)/(m2+1))*(m2+1)).astype("int8")
استفاده از مجموعه داده اصلی که دادههای مصنوعی از آن ایجاد شدهاند
ما میتوانیم مجموعه داده اصلی را که دادههای مصنوعی این مسابقه از آن ایجاد شده است، به عنوان خردهفروشی پیشنهادی سازنده در نظر بگیریم. و دادههای این مسابقه را به عنوان قیمتهای فروشگاههای جداگانه در نظر بگیریم. بنابراین، میتوانیم با دادن دانش MSRP به هر سطر به پیشبینیها کمک کنیم:
tmp = orig.groupby("Weight Capacity (kg)").Price.mean()
tmp.name = "orig_price"
train = train.merge(tmp, on="Weight Capacity (kg)", how="left")
ویژگیهای تقسیم
پس از ایجاد ستونهای جدید با groupby(COL1)[COL2].agg(STAT)، میتوانیم این ستونهای جدید را برای ایجاد ستونهای جدیدتر ترکیب کنیم. به عنوان مثال:
# COUNT PER NUNIQUE
X_train['TE1_wc_count_per_nunique'] = X_train['TE1_wc_count']/X_train['TE1_wc_nunique']
# STD PER COUNT
X_train['TE1_wc_std_per_count'] = X_train['TE1_wc_std']/X_train['TE1_wc_count']
خلاصه
نتیجه مقام اول در این مسابقه Kaggle فقط مربوط به یافتن ویژگیهای مناسب نبود - بلکه مربوط به داشتن سرعت برای یافتن آنها بود. مهندسی ویژگی همچنان برای به حداکثر رساندن عملکرد مدل جدولی ضروری است، اما رویکرد سنتی با استفاده از CPUها اغلب به یک مانع برخورد میکند و کشف گسترده ویژگی را به طور بازدارنده کند میکند.
NVIDIA cuDF-pandas در حال تغییر دادن چیزی است که ممکن است. با تسریع عملیات pandas بر روی GPU، این امکان را فراهم میکند تا به طور انبوه به اکتشاف و تولید ویژگیهای جدید در بازههای زمانی به شدت کاهش یافته بپردازیم. این به ما امکان میدهد بهترین ویژگیها را پیدا کنیم و مدلهای دقیقتری نسبت به قبل بسازیم. کد منبع و پستهای مرتبط در بحث Kaggle را در اینجا و در اینجا مشاهده کنید.
اگر میخواهید اطلاعات بیشتری کسب کنید، کارگاه GTC 2025 ما را در مورد مهندسی ویژگی یا به ارمغان آوردن محاسبات تسریعشده به علم داده در پایتون بررسی کنید، یا در دورههای مسیر یادگیری DLI ما برای علم داده ثبت نام کنید.